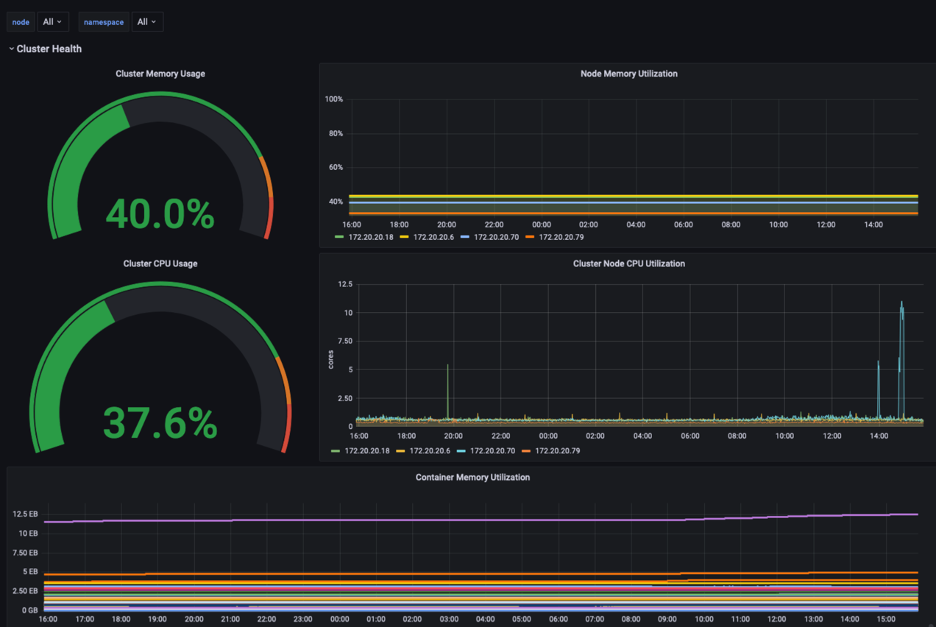
Kube-prometheus is a deployment method for the full Prometheus stack that administrators can easily deploy into a Kubernetes cluster. It contains several components:
- Prometheus for metric collection
- Alertmanager for metric alerts and notification
- Grafana for a graphical user interface
- A set of Kubernetes-specific exporters which function as metric collection agents
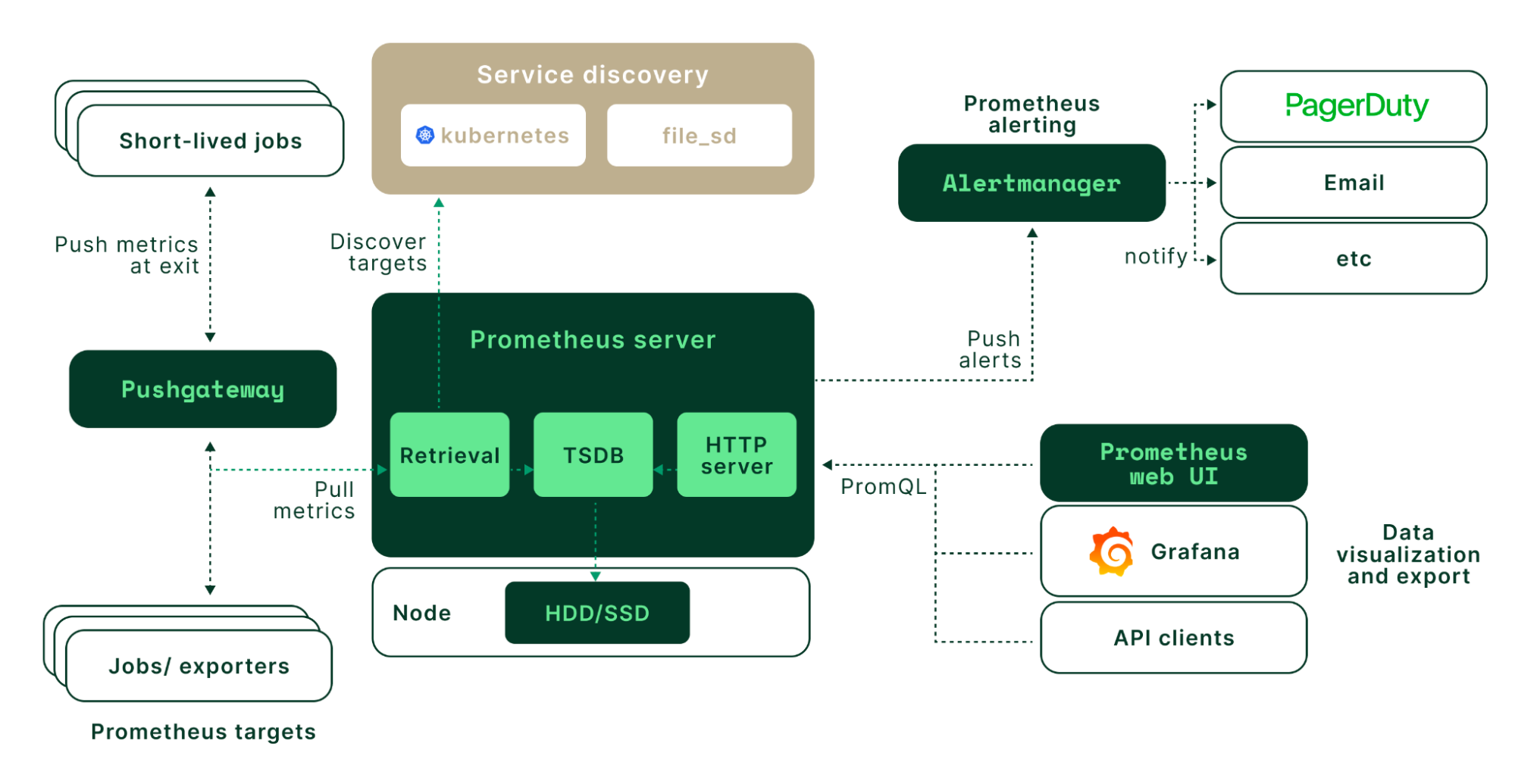
A diagram of the Prometheus architecture. (Source)
Prometheus
Prometheus is the core component of the kube-prometheus stack. It is the metric collection engine that collects metrics from agents and stores them in its internal time series database. In Prometheus, the collection process is called scraping, and the collection agents are known as exporters.
Prometheus uses a pull method of metric collection. Exporters expose their underlying metrics via an HTTP endpoint, and Prometheus scrapes these endpoints for measured data at a configured interval. The default scrape frequency for Kubernetes metrics is 30 seconds.
The Prometheus database has a multi-dimensional data model with time series data identified by metric name and key/value pairs. This database is queried using PromQL, a flexible query language to leverage this dimensionality.
In kube-prometheus, Prometheus is deployed as a highly available component with two replicas by default.
Kubernetes Exporters
There are hundreds of Prometheus exporters available. Additionally, there are several libraries for creating your own exporter. Kube-prometheus comes with several exporters for providing metric data pertinent to Kubernetes, including kube-state-metrics (KSM) and node-exporter.
Kube-state-metrics (KSM)
KSM is a deployment of the image quay.io/coreos/kube-state-metrics. This exporter exports metrics directly from the Kubernetes API server. It generates metrics about the internal Kubernetes objects, such as deployments, services, nodes, and pods.
Example metrics provided by kube-state-metrics include:
- kube_deployment_status_condition: condition and health status of a deployment
- kube_node_status_condition: condition or health of the underlying cluster nodes
- kube_pod_info: information about Pods such as namespace, IP address, and node
A reference of all metrics provided by kube-state-metrics exporter can be found here.
Node-exporter
Node-exporter is a daemonset of the image quay.io/prometheus/node-exporter. This exporter exports metrics from the underlying cluster nodes. It generates metrics related to server resources, such as load average, CPU, memory, and storage performance.
Example metrics provided by node-exporter include:
- node_load1: 1-minute average load and is read from the hosts /proc/loadavg file
- node_cpu_seconds_total: how many seconds each CPU spent performing work. The data is populated from the host file /proc/stat
- node_memory_MemAvailable_bytes: the amount of available memory, including caches and buffers that can be opened. The data is populated from the host file /proc/meminfo
- node_disk_io_now: the current disk input and output operations performed. It is read from the hosts /proc/diskstats file.
A reference of all collectors that generate metrics provided by node-exporter can be found here.