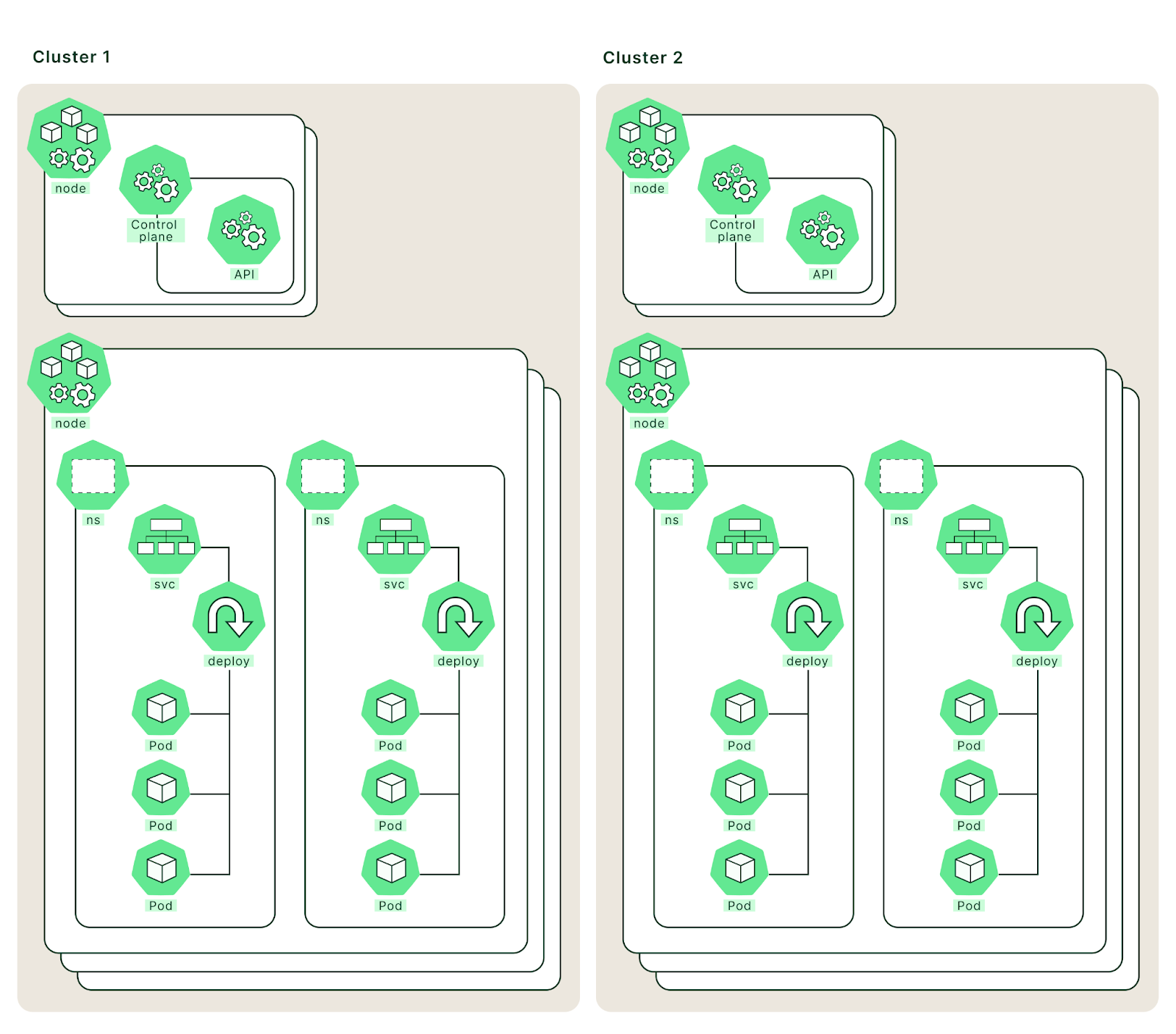
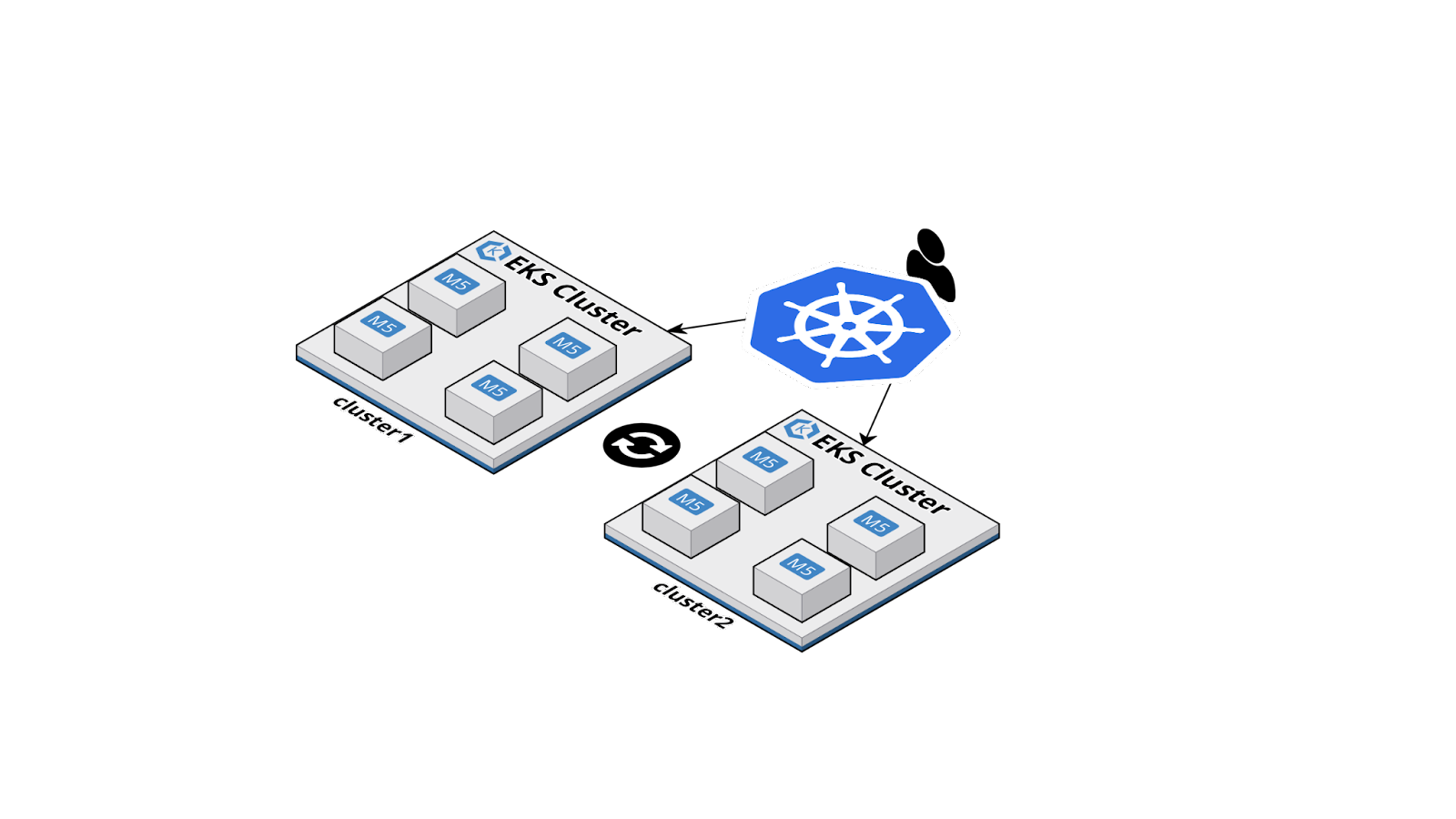
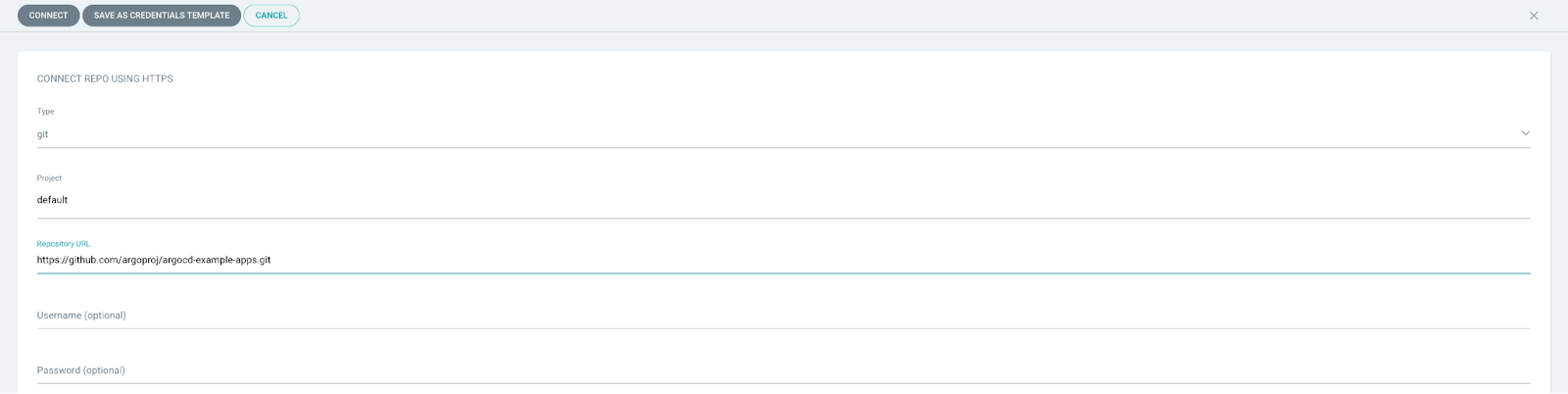
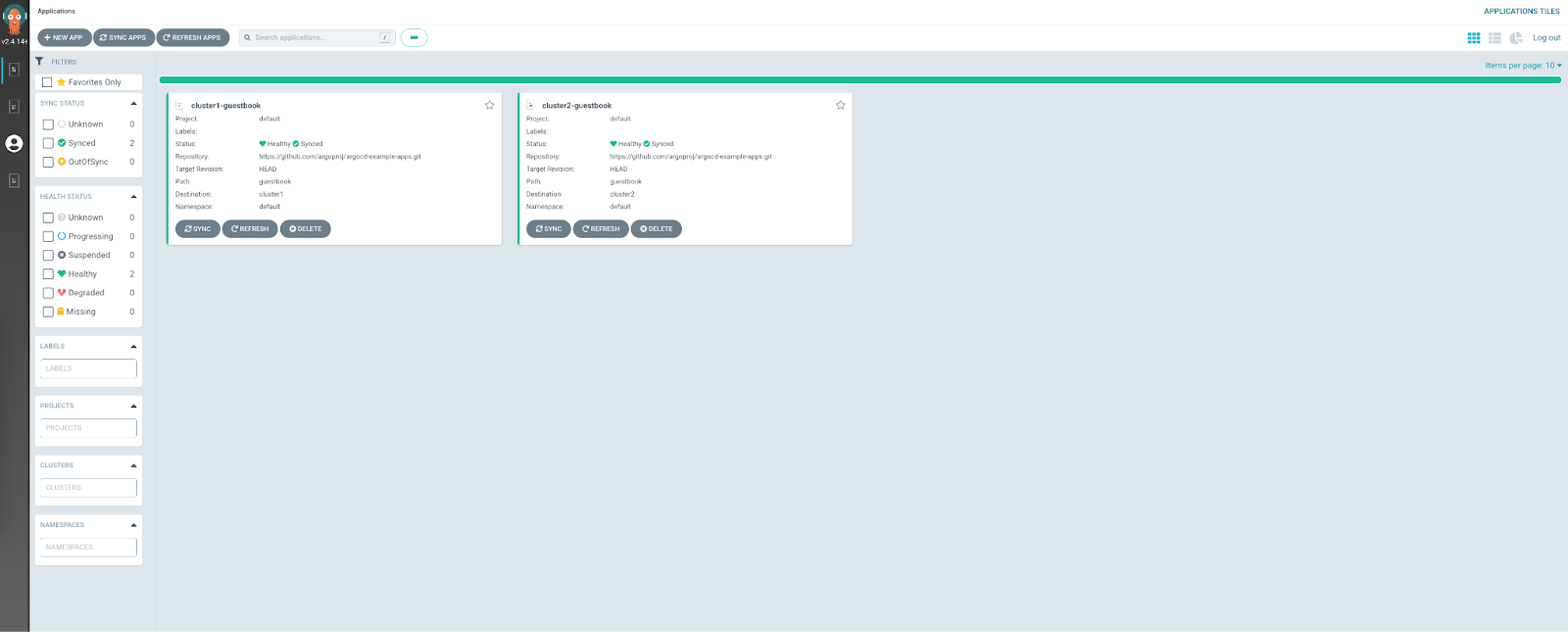
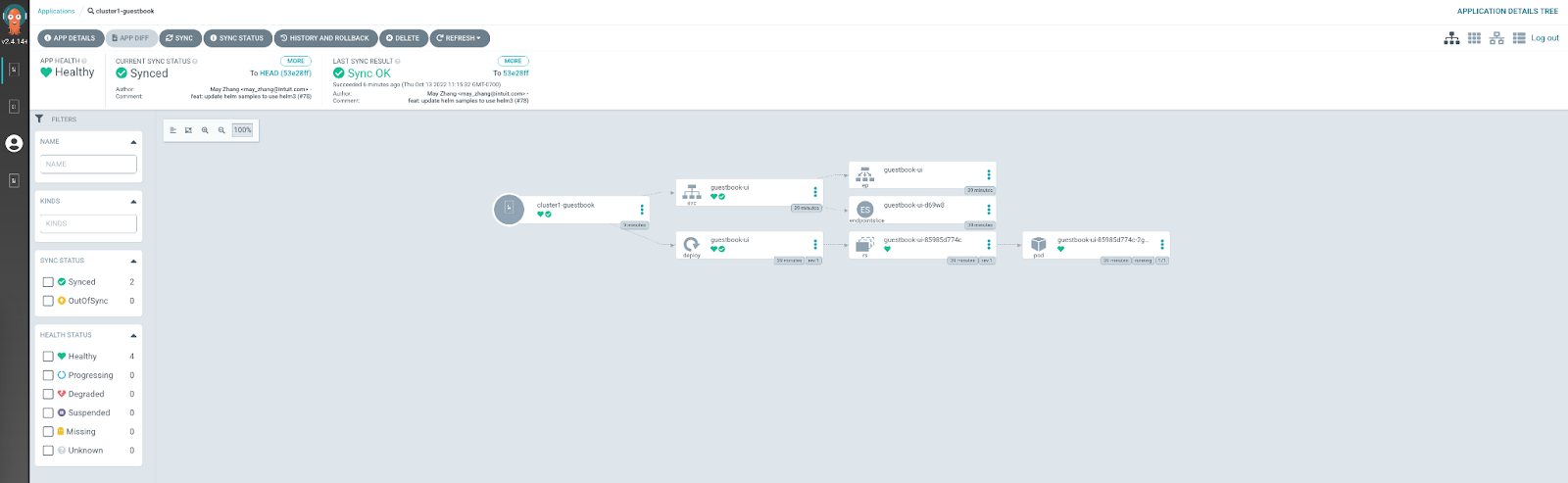
A logical representation of two EKS clusters.
Begin by renaming cluster contexts for convenience:
$ kubectl config rename-context <cluster1 context> cluster1
$ kubectl config rename-context <cluster2 context> cluster1
Going forward these clusters will be referred to by these aliases. However, the strings cluster1 and cluster2 are arbitrary and any names can be used. Here, cluster1 will be used as the primary and cluster2 as the secondary.
Federation with kubefed
Add the Helm repository for kubefed:
$ helm repo add kubefed-charts https://raw.githubusercontent.com/kubernetes-sigs/kubefed/master/charts
"kubefed-charts" has been added to your repositories
Confirm the addition:
$ helm repo list
NAME URL
kubefed-charts https://raw.githubusercontent.com/kubernetes-sigs/kubefed/master/charts
Setup the shell environment (Mac on AMD64 shown):
$ VERSION=0.10.0
$ OS=darwin
$ ARCH=amd64
Install the kubefed chart on the primary clusters (the namespace value is arbitrary and can be substituted for any preferred string):
$ helm \
--namespace kube-federation-system \
upgrade -i kubefed kubefed-charts/kubefed \
--version=$VERSION \
--create-namespace \
--kube-context cluster1
Release "kubefed" does not exist. Installing it now.
NAME: kubefed
LAST DEPLOYED: Wed Oct 12 10:10:15 2022
NAMESPACE: kube-federation-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
Confirm the installation:
$ helm list --namespace kube-federation-system
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kubefed kube-federation-system 1 2022-10-12 10:10:15.127896 -0700 PDT deployed kubefed-0.10.0
The version string 0.10.0 matches the current stable release and should be adjusted to remain up-to-date.
Install the kubefedctl utility (Mac commands shown):
$ curl -LO https://github.com/kubernetes-sigs/kubefed/releases/download/v${VERSION}/kubefedctl-${VERSION}-${OS}-${ARCH}.tgz
$ tar -zxf kubefedctl-0.10.0-darwin-amd64.tgz
$ chmod u+x kubefedctl
$ sudo mv kubefedctl /usr/local/bin/
Verify the install:
$ kubefedctl version
kubefedctl version: version.Info{Version:"v0.9.2-29-g76ad91b1f", GitCommit:"76ad91b1fbdedee0c6733ccaa00d7165965b69fe", GitTreeState:"clean", BuildDate:"2022-08-10T10:03:33Z", GoVersion:"go1.16.6", Compiler:"gc", Platform:"darwin/amd64"}
Using the kubefedctl utility, federate the two clusters:
$ kubefedctl join cluster1 \
--cluster-context cluster1 \
--host-cluster-context cluster1 \
--v=2
I1012 10:38:56.201019 53204 join.go:162] Args and flags: name cluster1, host: cluster1, host-system-namespace: kube-federation-system, kubeconfig: , cluster-context: cluster1, secret-name: , dry-run: false
I1012 10:38:57.620465 53204 join.go:243] Performing preflight checks.
I1012 10:38:57.888275 53204 join.go:249] Creating kube-federation-system namespace in joining cluster
I1012 10:38:57.979304 53204 join.go:407] Already existing kube-federation-system namespace
I1012 10:38:57.979335 53204 join.go:256] Created kube-federation-system namespace in joining cluster
I1012 10:38:57.979348 53204 join.go:429] Creating service account in joining cluster: cluster1
I1012 10:38:58.076172 53204 join.go:439] Created service account: cluster1-cluster1 in joining cluster: cluster1
I1012 10:38:58.166987 53204 join.go:449] Created service account token secret: cluster1-cluster1 in joining cluster: cluster1
I1012 10:38:58.167025 53204 join.go:476] Creating cluster role and binding for service account: cluster1-cluster1 in joining cluster: cluster1
I1012 10:38:58.723498 53204 join.go:485] Created cluster role and binding for service account: cluster1-cluster1 in joining cluster: cluster1
I1012 10:38:58.723533 53204 join.go:888] Creating cluster credentials secret in host cluster
I1012 10:38:59.093922 53204 join.go:982] Created secret in host cluster named: cluster1-25l7f
I1012 10:38:59.484364 53204 join.go:301] Created federated cluster resource
$ kubefedctl join cluster2 \
--cluster-context cluster2 \
--host-cluster-context cluster1 \
--v=2
I1012 10:42:15.157770 53226 join.go:162] Args and flags: name cluster2, host: cluster1, host-system-namespace: kube-federation-system, kubeconfig: , cluster-context: cluster2, secret-name: , dry-run: false
I1012 10:42:16.578734 53226 join.go:243] Performing preflight checks.
I1012 10:42:16.924855 53226 join.go:249] Creating kube-federation-system namespace in joining cluster
I1012 10:42:17.010982 53226 join.go:407] Already existing kube-federation-system namespace
I1012 10:42:17.011011 53226 join.go:256] Created kube-federation-system namespace in joining cluster
I1012 10:42:17.011024 53226 join.go:429] Creating service account in joining cluster: cluster2
I1012 10:42:17.104375 53226 join.go:439] Created service account: cluster2-cluster1 in joining cluster: cluster2
I1012 10:42:17.190758 53226 join.go:449] Created service account token secret: cluster2-cluster1 in joining cluster: cluster2
I1012 10:42:17.190777 53226 join.go:476] Creating cluster role and binding for service account: cluster2-cluster1 in joining cluster: cluster2
I1012 10:42:17.724388 53226 join.go:485] Created cluster role and binding for service account: cluster2-cluster1 in joining cluster: cluster2
I1012 10:42:17.724415 53226 join.go:888] Creating cluster credentials secret in host cluster
I1012 10:42:18.099499 53226 join.go:982] Created secret in host cluster named: cluster2-5p5r4
I1012 10:42:18.475912 53226 join.go:301] Created federated cluster resource
Using the code provided in the kubefed Git repository and test the federation:
$ git clone https://github.com/kubernetes-sigs/kubefed.git && \
cd kubefed && \
kubefedctl enable ClusterRoleBinding
$ kubectl --context=cluster1 apply \
-f example/sample1/namespace.yaml \
-f example/sample1/federatednamespace.yaml
$ for r in configmaps secrets service deployment serviceaccount job; do
for c in cluster1 cluster2; do
echo; echo ------------ ${c} resource: ${r} ------------; echo
kubectl --context=${c} -n test-namespace get ${r}
echo; echo
done
Done
Output should be similar to:
------------ cluster1 resource: configmaps ------------
NAME DATA AGE
kube-root-ca.crt 1 5m21s
test-configmap 1 53s
------------ cluster2 resource: configmaps ------------
NAME DATA AGE
kube-root-ca.crt 1 5m20s
test-configmap 1 53s
------------ cluster1 resource: secrets ------------
NAME TYPE DATA AGE
default-token-tqf7m kubernetes.io/service-account-token 3 5m22s
test-secret Opaque 1 52s
test-serviceaccount-token-zz9v6 kubernetes.io/service-account-token 3 52s
------------ cluster2 resource: secrets ------------
NAME TYPE DATA AGE
default-token-5tvzp kubernetes.io/service-account-token 3 5m21s
test-secret Opaque 1 53s
test-serviceaccount-token-2gspg kubernetes.io/service-account-token 3 52s
------------ cluster1 resource: service ------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test-service NodePort 10.100.219.142 <none> 80:30313/TCP 52s
------------ cluster2 resource: service ------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test-service NodePort 10.100.97.86 <none> 80:30708/TCP 53s
------------ cluster1 resource: deployment ------------
NAME READY UP-TO-DATE AVAILABLE AGE
test-deployment 3/3 3 3 55s
------------ cluster2 resource: deployment ------------
NAME READY UP-TO-DATE AVAILABLE AGE
test-deployment 5/5 5 5 54s
------------ cluster1 resource: serviceaccount ------------
NAME SECRETS AGE
default 1 5m24s
test-serviceaccount 1 54s
------------ cluster2 resource: serviceaccount ------------
NAME SECRETS AGE
default 1 5m23s
test-serviceaccount 1 54s
------------ cluster1 resource: job ------------
NAME COMPLETIONS DURATION AGE
test-job 0/1 55s 55s
------------ cluster2 resource: job ------------
NAME COMPLETIONS DURATION AGE
test-job 0/1 of 2 56s 56s
While this confirms that federation has been successful, testing a failure is always a good idea - remove cluster2 from federation and re-check resources:
$ kubectl -n test-namespace patch federatednamespace test-namespace \
--type=merge \
-p '{"spec": {"placement": {"clusters": [{"name": "cluster1"}]}}}'
federatednamespace.types.kubefed.io/test-namespace patched
$ for r in configmaps secrets service deployment serviceaccount job; do
for c in cluster1 cluster2; do
echo; echo ------------ ${c} resource: ${r} ------------; echo
kubectl --context=${c} -n test-namespace get ${r}
echo; echo
done
Done
Expect output similar to:
------------ cluster1 resource: configmaps ------------
NAME DATA AGE
kube-root-ca.crt 1 11m
test-configmap 1 7m9s
------------ cluster2 resource: configmaps ------------
No resources found in test-namespace namespace.
------------ cluster1 resource: secrets ------------
NAME TYPE DATA AGE
default-token-tqf7m kubernetes.io/service-account-token 3 11m
test-secret Opaque 1 7m8s
test-serviceaccount-token-zz9v6 kubernetes.io/service-account-token 3 7m8s
------------ cluster2 resource: secrets ------------
No resources found in test-namespace namespace.
------------ cluster1 resource: service ------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test-service NodePort 10.100.219.142 <none> 80:30313/TCP 7m8s
------------ cluster2 resource: service ------------
No resources found in test-namespace namespace.
------------ cluster1 resource: deployment ------------
NAME READY UP-TO-DATE AVAILABLE AGE
test-deployment 3/3 3 3 7m11s
------------ cluster2 resource: deployment ------------
No resources found in test-namespace namespace.
------------ cluster1 resource: serviceaccount ------------
NAME SECRETS AGE
default 1 11m
test-serviceaccount 1 7m10s
------------ cluster2 resource: serviceaccount ------------
No resources found in test-namespace namespace.
------------ cluster1 resource: job ------------
NAME COMPLETIONS DURATION AGE
test-job 0/1 7m12s 7m12s
------------ cluster2 resource: job ------------
No resources found in test-namespace namespace.
The cluster can be re-added via the same patch method:
$ kubectl -n test-namespace patch federatednamespace test-namespace \
--type=merge \
-p '{"spec": {"placement": {"clusters": [{"name": "cluster1"}, {"name": "cluster2"}]}}}'
federatednamespace.types.kubefed.io/test-namespace patched
Cleanup is always important, so don’t forget to delete the namespace:
$ kubectl --context=cluster1 delete ns test-namespace
What’s next?
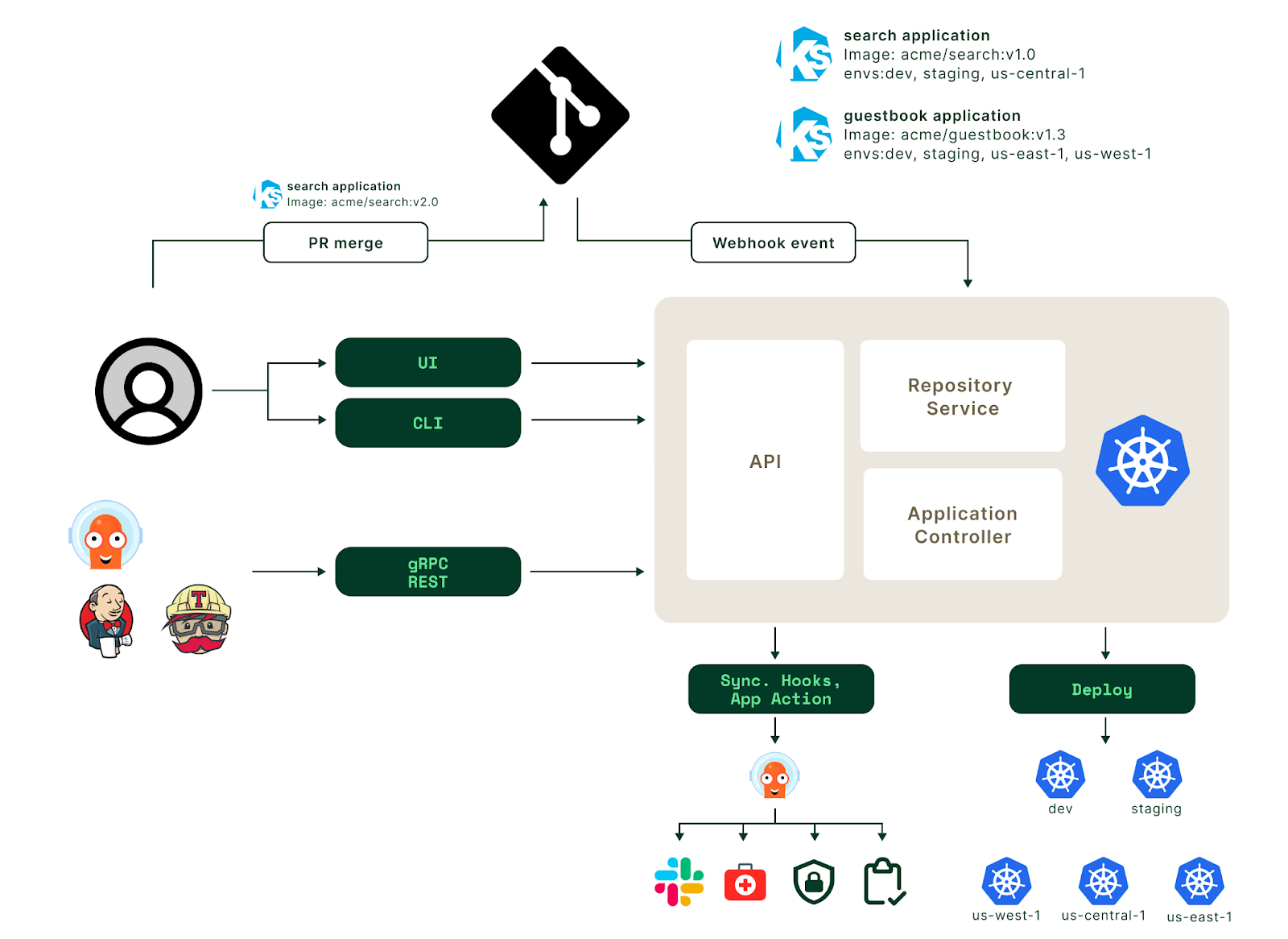
Aside from perhaps setting up some status monitoring to ensure that resources remain synchronized, there’s not much more to this setup. Kubefed keeps resources 1:1 across the mirrored clusters. Other tools such as ArgoCD (below) or Kyverno can be added to enhance the management of the cluster, but these are outside of the scope of the multi-cluster configuration itself and would be applicable to any Kubernetes cluster.