Once deployment is complete, you will see a confirmation message.
Apply complete!
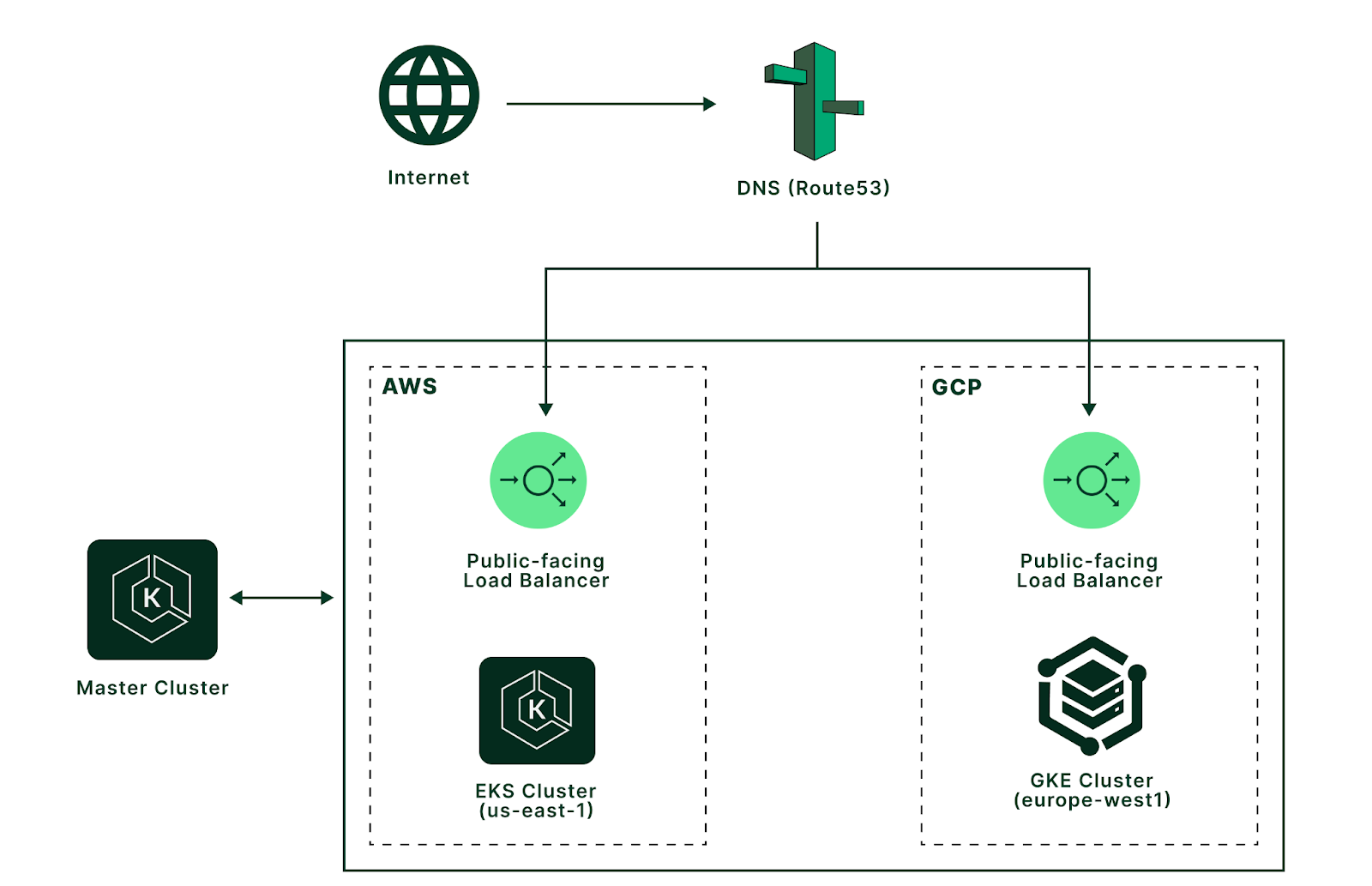
Access clusters from your local terminal
To access the AWS EKS clusters for the local terminal, execute the below commands.
> aws eks update-kubeconfig --region us-east-1 --name master-cluster
> aws eks update-kubeconfig --region us-east-1 --name aws-federated-cluster-a
To access the GKE cluster from the local terminal, execute below commands.
> export USE_GKE_GCLOUD_AUTH_PLUGIN=true
> gcloud components install gke-gcloud-auth-plugin
> gcloud container clusters get-credentials --region europe-west1 gcp-federated-cluster-a
Above commands will install a component called gke-gcloud-auth-plugin. This is required to enable GKE access from the local terminal.
Next, we will rename these clusters for easier reference from the kubectl and deployment files.
> kubectl config rename-context arn:aws:eks:us-east-1:979450158315:cluster/master-cluster master-cluster
> kubectl config rename-context arn:aws:eks:us-east-1:979450158315:cluster/aws-federated-cluster-a aws-federated-cluster-a
> kubectl config rename-context gke_abhidevops-348717_europe-west1_gcp-federated-cluster-a gcp-federated-cluster-a
For the first two commands, 979450158315 is the AWS account ID.
For the third command, abhidevops-348717 defines the GCP project ID.
These values will be different in your case.
Connect clusters using Kubernetes Federation
Next, we will install Kubefed to manage multiple Kubernetes clusters using Kubernetes Federation.
First, we will select the master-cluster context.
> kubectl config use-context master-cluster
Switched to context "master-cluster".
Install Helm to deploy the Kubefed in the cluster. Once installed, verify the Helm version.
> helm version --short
To install kubefed in the master cluster, run the below commands:
> helm repo add kubefed-charts https://raw.githubusercontent.com/kubernetes-sigs/kubefed/master/charts
> helm repo update
Next, install a kubefed helm chart to the cluster, execute below command:
> helm --namespace kube-federation-system upgrade -i kubefed kubefed-charts/kubefed --create-namespace
The above command will install the kubefed in the kube-federation-system namespace.
To verify resources added by Kubefed in the master cluster, run the below command:
> kubectl get all -n kube-federation-system
To register the AWS EKS and GCP GKE clusters to the master cluster, and label the clusters as federation-enabled=true, execute below commands.
> kubefedctl join aws-federated-cluster-a --cluster-context aws-federated-cluster-a --host-cluster-context master-cluster --v=2
> kubefedctl join gcp-federated-cluster-a --cluster-context gcp-federated-cluster-a --host-cluster-context master-cluster --v=2
> kubectl label kubefedclusters -n kube-federation-system aws-federated-cluster-a federation-enabled=true
> kubectl label kubefedclusters -n kube-federation-system gcp-federated-cluster-a federation-enabled=true
Deploy Kubernetes deployments and services across clusters
To create all the Kubernetes deployment manifests, create a directory named k8s-deployments.
First, we will create a namespace on the master cluster and then deploy the namespace to all the federated clusters.
Create a file federated-ns.yaml in the k8s-deployments directory with the code block below.
apiVersion: v1
kind: Namespace
metadata:
name: federated-ns
---
apiVersion: types.kubefed.io/v1beta1
kind: FederatedNamespace
metadata:
name: federated-ns
namespace: federated-ns
spec:
placement:
clusterSelector:
matchLabels:
federation-enabled: "true"
This manifest defines two resources Namespace and FederatedNamespace.
To apply these resources, execute:
> kubectl apply -f federated-ns.yaml
namespace/federated-ns created
federatednamespace.types.kubefed.io/federated-ns created
Next, we will create a sample-app deployment in the federated clusters.
Create a file called federated-deployment.yaml with below code block.
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: sample-app
namespace: federated-ns
spec:
placement:
clusterSelector:
matchLabels:
federation-enabled: "true"
template:
spec:
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- image: k8s.gcr.io/echoserver:1.10
name: sample-app
ports:
- containerPort: 8080
name: http
- containerPort: 8443
name: https
To apply this deployment, execute:
> kubectl apply -f federated-deployment.yaml
federateddeployment.types.kubefed.io/sample-app created
To verify the deployment of the sample-app, execute:
> kubectl get deployments --namespace federated-ns --context aws-federated-cluster-a
NAME READY UP-TO-DATE AVAILABLE AGE
sample-app 1/1 1 1 52s
> kubectl get deployments --namespace federated-ns --context gcp-federated-cluster-a
NAME READY UP-TO-DATE AVAILABLE AGE
sample-app 1/1 1 1 61s
We can confirm the deployment is successfully created in both clusters.
Next, we will create a Kubernetes Service of type LoadBalancer. This service will expose the sample-app to the outside of the cluster and create a load balancer in both cloud providers i.e., AWS and GCP.
Create a file named federated-svc.yaml.
apiVersion: types.kubefed.io/v1beta1
kind: FederatedService
metadata:
name: sample-app-svc-lb
namespace: federated-ns
spec:
placement:
clusterSelector:
matchLabels:
federation-enabled: "true"
template:
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: sample-app
type: LoadBalancer
To create this service, execute:
> kubectl apply -f federated-svc.yaml
federatedservice.types.kubefed.io/sample-app-svc-lb created
To verify the service and loadbalancer creation, execute:
> kubectl get service --namespace federated-ns --context aws-federated-cluster-a
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
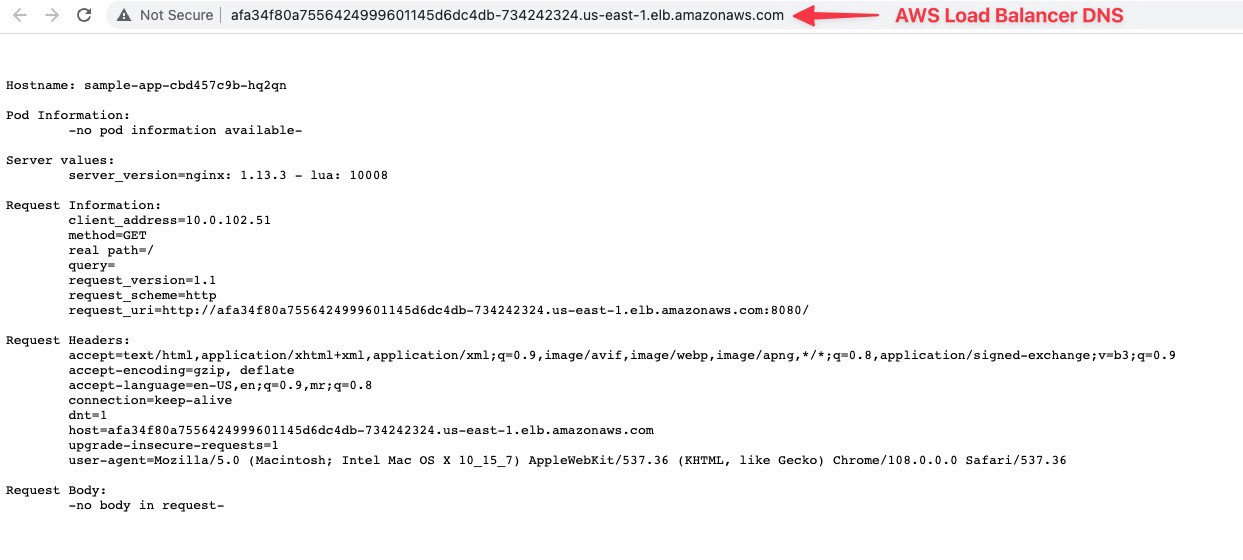
sample-app-svc-lb LoadBalancer 172.20.106.96 afa34f80a7556424999601145d6dc4db-734242324.us-east-1.elb.amazonaws.com 80:31439/TCP 32s
> kubectl get service --namespace federated-ns --context gcp-federated-cluster-a
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sample-app-svc-lb LoadBalancer 10.70.193.74 34.140.8.249 80:32724/TCP 3m5s
We can verify the load balancer created in both the cluster across AWS and GCP.
We can browse the sample app using the load balancers’ public endpoint to verify the load balancer is working.