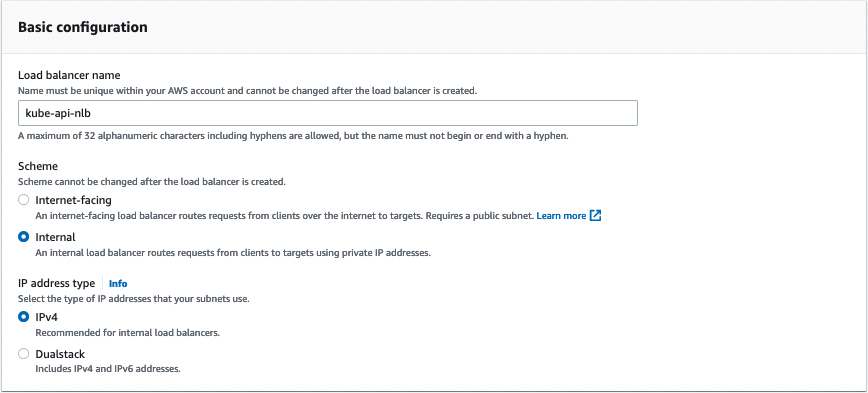
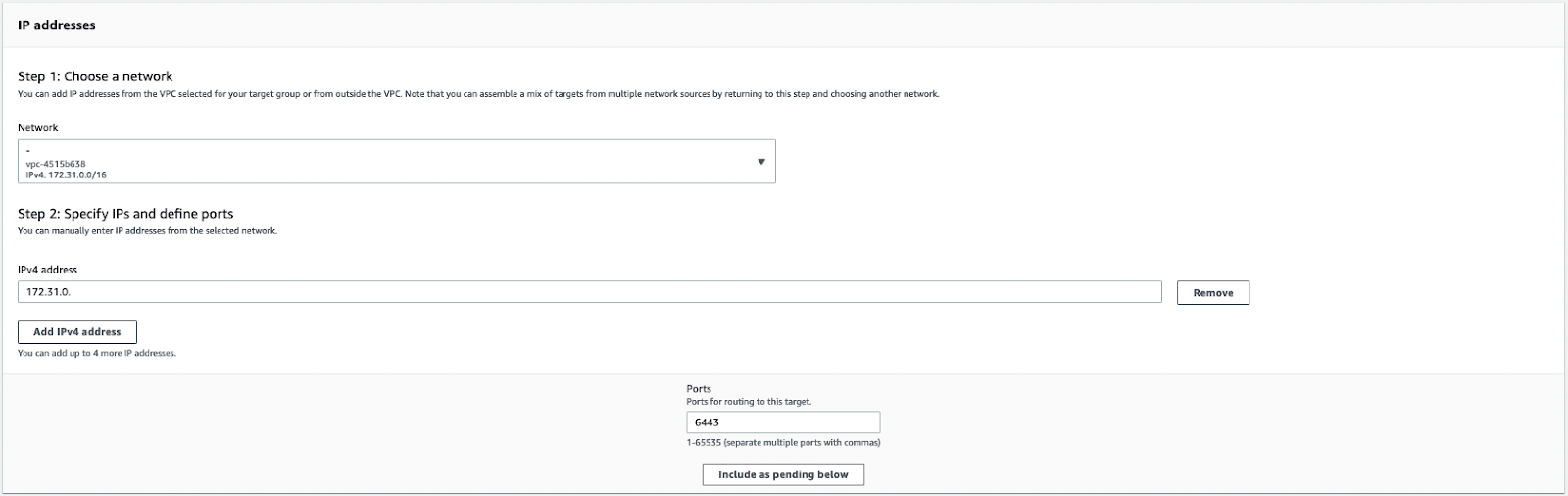
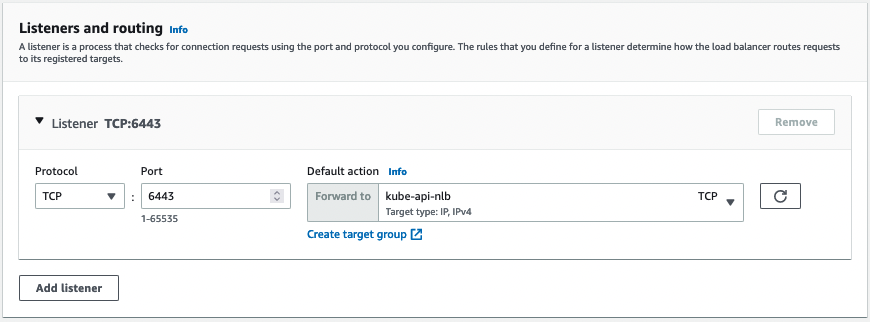
Deploying a service to each cluster
To demonstrate how our cluster works, let's deploy a service to each cluster.
$ for ctx in west east; do
echo "Adding test services on cluster: ${ctx} ........."
kubectl --context=${ctx} apply \
-n test -k "github.com/linkerd/website/multicluster/${ctx}/"
kubectl --context=${ctx} -n test \
rollout status deploy/podinfo || break
echo "-------------"
done
> Note: if using aliases other than “east” and “west”, this command will not work as-written because the Linkerd-provided multicluster application assumes “east” and “west” respectively in the path github.com/linkerd/website/multicluster/${ctx}/
With services deployed, configure mirroring for the east service. Linkerd requires that this is configured explicitly.
$ kubectl --context=east label svc -n test podinfo mirror.linkerd.io/exported=true
Reviewing services on the west cluster should now return two entries.
$ kubectl --context=west -n test get svc -l app=podinfo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
podinfo ClusterIP 1.2.3.4 9898/TCP,9999/TCP 54m
podinfo-east ClusterIP 1.2.3.5 9898/TCP,9999/TCP 46m
Since packets must be routed between the clusters, it is important that the endpoint IP address on west matches the gateway IP address on east.
$ kubectl --context=west -n test get endpoints podinfo-east \
-o 'custom-columns=ENDPOINT_IP:.subsets[*].addresses[*].ip'
ENDPOINT_IP
10.20.30.40
$ kubectl --context=east -n linkerd-multicluster get svc linkerd-gateway \
-o "custom-columns=GATEWAY_IP:.status.loadBalancer.ingress[*].ip"
GATEWAY_IP
10.20.30.40
If this is not the case, then something has gone wrong and the two clusters are not properly linked. Specifically, requests on west for services on east will not route properly and never succeed.
Time to send some requests! Recall that requests must come from pods already on the mesh, therefore exec into west's frontend pod.
$ kubectl --context=west -n test exec -c nginx -it \
$(kubectl --context=west -n test get po -l app=frontend \
--no-headers -o custom-columns=:.metadata.name) \
-- /bin/sh -c "apk add curl && curl http://podinfo-east:9898"
Expect output similar to the output below, specifically look for "greetings from east":
OK: 26 MiB in 42 packages
{
"hostname": "podinfo-694fff64fb-hlslg",
"version": "4.0.2",
"revision": "b4138fdb4dce7b34b6fc46069f70bb295aa8963c",
"color": "#007bff",
"logo": "https://raw.githubusercontent.com/stefanprodan/podinfo/gh-pages/cuddle_clap.gif",
"message": "greetings from east",
"goos": "linux",
"goarch": "amd64",
"runtime": "go1.14.3",
"num_goroutine": "9",
"num_cpu": "2"
}
You can also verify mesh status with this command.
$ kubectl --context=west -n test get po -l app=frontend -o jsonpath='{.items[0].spec.containers[*].name}'
linkerd-proxy external nginx internal
The presence of a linkerd-proxy container confirms the pod is on-mesh.
With the routing verified, verify what happens when a pod that isn't on-mesh makes the same request.
$ kubectl --context=west -n test run -it --rm --image=alpine:3 test -- \
/bin/sh -c "apk add curl && curl -vv http://podinfo-east:9898"
The output is quite different:
If you don't see a command prompt, try pressing enter.
(1/5) Installing ca-certificates (20220614-r0)
(2/5) Installing brotli-libs (1.0.9-r6)
(3/5) Installing nghttp2-libs (1.47.0-r0)
(4/5) Installing libcurl (7.83.1-r3)
(5/5) Installing curl (7.83.1-r3)
Executing busybox-1.35.0-r17.trigger
Executing ca-certificates-20220614-r0.trigger
OK: 8 MiB in 19 packages
* Trying 10.100.67.184:9898...
* Connected to podinfo-east (10.100.67.184) port 9898 (#0)
> GET / HTTP/1.1
> Host: podinfo-east:9898
> User-Agent: curl/7.83.1
> Accept: */*
>
* Empty reply from server
* Closing connection 0
curl: (52) Empty reply from server
Session ended, resume using 'kubectl attach test -c test -i -t' command when the pod is running
pod "test" deleted
Even though the request comes from an on-mesh cluster, and a namespace with on-mesh resources, the pod from which the request is executed is not itself on-mesh and therefore the connection is refused.
What's next?
Services shared between different clusters and cloud providers are great, but if something happens to the primary cluster, problems arise. Service mesh architectures can use traffic spitting to address this problem.
Linkerd uses the service mesh interface (SMI) to implement TrafficSplit. Let's install that dependency.
$ curl --proto '=https' --tlsv1.2 -sSfL https://linkerd.github.io/linkerd-smi/install | sh
linkerd smi --context=west install --skip-checks | kubectl apply -f -
linkerd smi --context=west check
linkerd-smi
-----------
√ linkerd-smi extension Namespace exists
√ SMI extension service account exists
√ SMI extension pods are injected
√ SMI extension pods are running
√ SMI extension proxies are healthy
Status check results are √
> Note: The use of skip-checks may be specific to deploying on EKS and is tied to the use of an older Linkerd library; more details are available in issue 8556
By adding a TrafficSplit resource (below) to the west cluster, requests will now be balanced 50-50 with east.
$ kubectl --context=west apply -f - <<EOF
apiVersion: split.smi-spec.io/v1alpha1
kind: TrafficSplit
metadata:
name: podinfo
namespace: test
spec:
service: podinfo
backends:
- service: podinfo
weight: 50
- service: podinfo-east
weight: 50
EOF
Requesting the frontend service repeatedly will alternate between east and west.
$ kubectl --context=west -n test exec -c nginx -it $(kubectl --context=west -n test get po -l app=frontend \
--no-headers -o custom-columns=:.metadata.name) -- /bin/sh -c "apk add curl && curl http://frontend:8080"
OK: 26 MiB in 42 packages
{
"hostname": "podinfo-694fff64fb-hlslg",
"version": "4.0.2",
"revision": "b4138fdb4dce7b34b6fc46069f70bb295aa8963c",
"color": "#007bff",
"logo": "https://raw.githubusercontent.com/stefanprodan/podinfo/gh-pages/cuddle_clap.gif",
"message": "greetings from east",
"goos": "linux",
"goarch": "amd64",
"runtime": "go1.14.3",
"num_goroutine": "9",
"num_cpu": "2"
}
$ kubectl --context=west -n test exec -c nginx -it $(kubectl --context=west -n test get po -l app=frontend \
--no-headers -o custom-columns=:.metadata.name) -- /bin/sh -c "apk add curl && curl http://frontend:8080"
OK: 26 MiB in 42 packages
{
"hostname": "podinfo-6d889c4df5-s66ch",
"version": "4.0.2",
"revision": "b4138fdb4dce7b34b6fc46069f70bb295aa8963c",
"color": "#6c757d",
"logo": "https://raw.githubusercontent.com/stefanprodan/podinfo/gh-pages/cuddle_clap.gif",
"message": "greetings from west",
"goos": "linux",
"goarch": "amd64",
"runtime": "go1.14.3",
"num_goroutine": "9",
"num_cpu": "2"
Of course, if the entire west cluster goes down, this still won't help without some extra wrapping from Global Traffic Management (GTM).