Apply the deployment :
kubectl apply -f demo-deployment.yaml
Step 3: Select the service type
ClusterIP Service
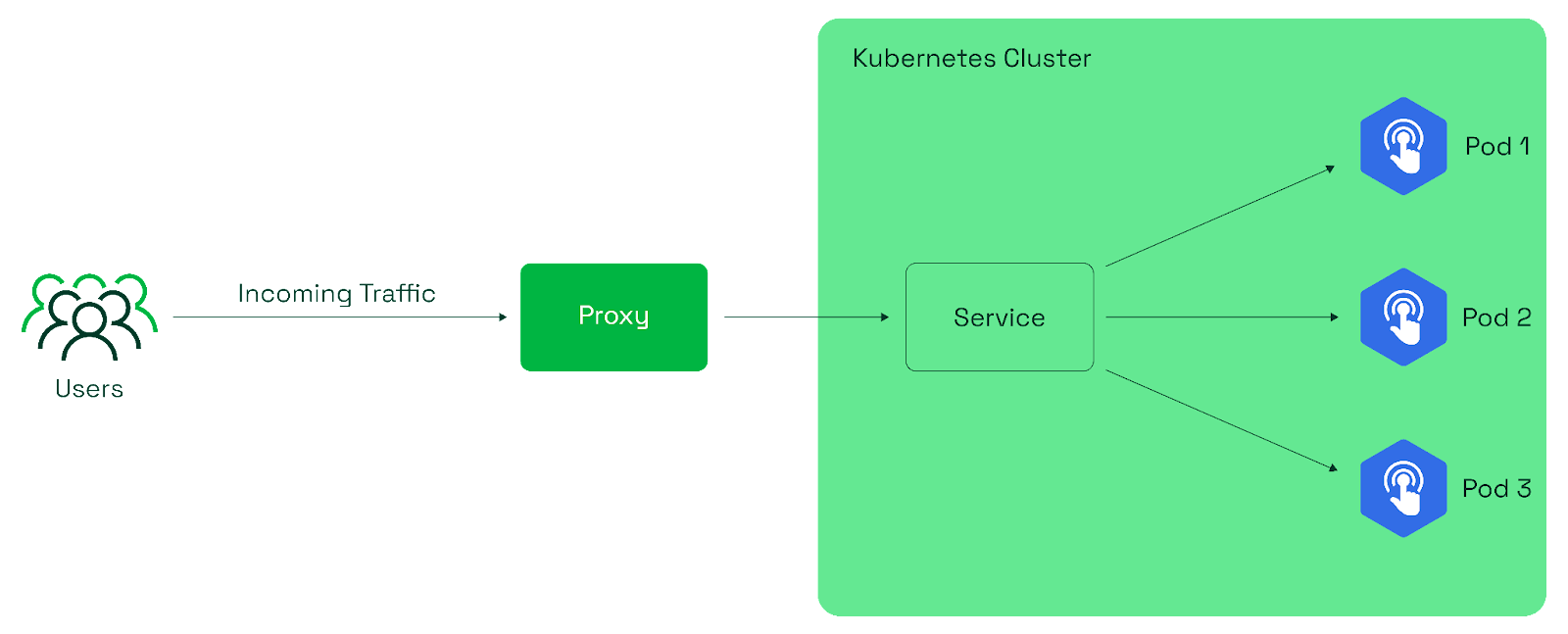
This type of service is only accessible within the Kubernetes cluster. It is suitable for scenarios where your application components need to communicate with each other within the cluster but shouldn't be directly accessible from outside.
Create a file named “clusterip-service.yaml” with the following content:
apiVersion: v1
kind: Service
metadata:
name: clusterip-service
spec:
type: ClusterIP
selector:
app: demo-app
ports:
- protocol: TCP
port: 80
targetPort: 80
Apply the service using the command:
kubectl apply -f clusterip-service.yaml
Verify the ClusterIP service by checking the service details:
kubectl get svc clusterip-service
This command will display the ClusterIP address assigned to the service.
Step 4: Verify the ClusterIP service
To verify that the ClusterIP functions as expected, create a busybox pod for testing using the following command:
kubectl run -i --tty busybox --image=busybox --restart=Never -- /bin/sh
Inside the busybox pod, use the wget command to access the ClusterIP service:
wget http://<clusterip>:<port>
You should be able to access the Apache default page, demonstrating that the ClusterIP service allows communication within the cluster.
To confirm that the ClusterIP service is limited to within the cluster, running the same wget command from a local machine will show that it is not accessible from outside the cluster.
NodePort Service
NodePort is a simple way to allow external access to your application. But it isn't suitable for production due to limitations like no built-in SSL termination.
To create a NodePort service, change the type to the following in the service yaml:
type: NodePort
After applying the service, verify the NodePort service by checking the service details and accessing the application externally:
kubectl get svc demo-nodeport
We can access our application by using any of the worker node's IP addresses along with the NodePort. To find the IP address of the worker node, we can use the following command:
kubectl get nodes -o wide
Replace NODE_IP with the IP address of one of your cluster nodes and NODE_PORT with the NodePort assigned to the service:
wget http://NODE_IP:NODE_PORT
This demonstrates that we can access the application not only from within the cluster but also from the external system, making NodePort services suitable for development and testing.
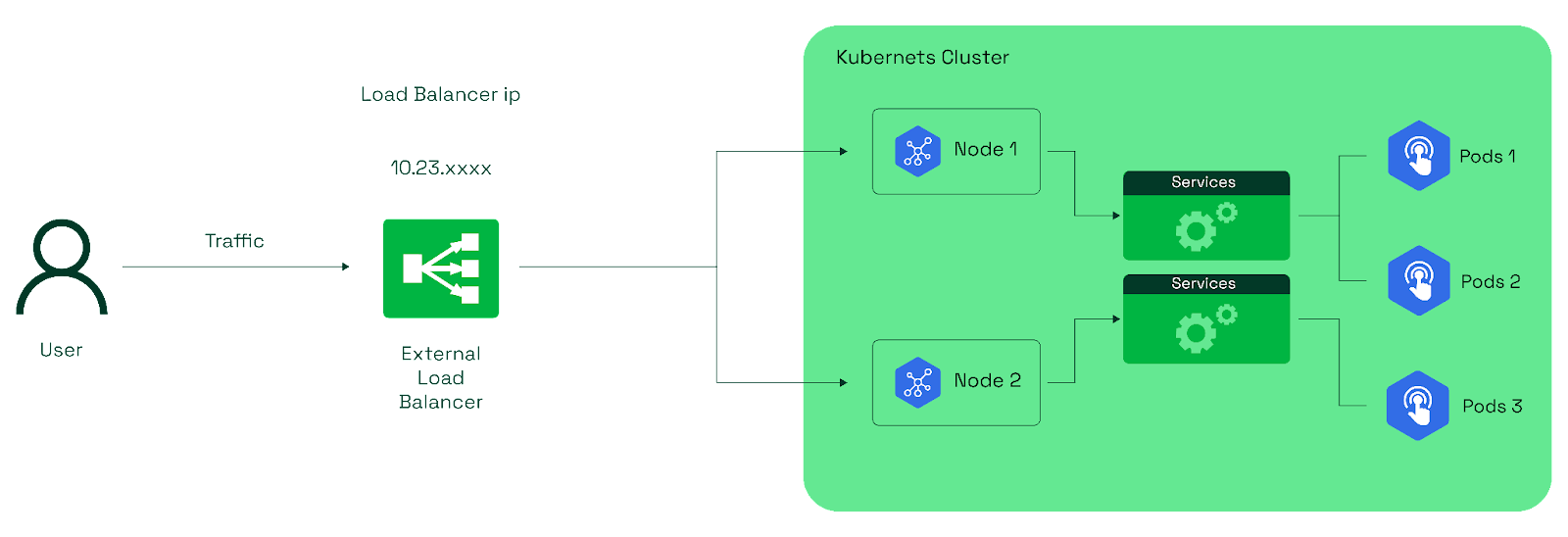
LoadBalancer Service
This is ideal for applications that require external access and automatic distribution of traffic across pods. It's well-suited for scenarios where high availability and scalability are essential.
Please note that the LoadBalancer service type is primarily designed for integration with external cloud platforms (e.g., AWS, GCP, Azure) that offer load-balancing services. This type of service might not behave the same way in local or on-premises Kubernetes setups.
To create a load balancer service, use the type in service:
type: LoadBalancer
Verify the LoadBalancer service by checking the service details and confirming the provisioned external IP:
kubectl get svc demo-loadbalancer
Here, the cloud provider's load balancer typically provides this external IP.
Once the cloud provider's load balancer assigns the external IP, we can use wget to access the Apache default page. Open a terminal or command prompt and run the following command:
wget http://<External-IP>
This will retrieve the content of the Apache default page and save it to your local directory.
Best practice #2: Use Kubernetes health checks and probes
Health checks and probes are essential for a robust Kubernetes load balancer setup. They ensure that your application's backend pods are responsive, healthy, and capable of handling incoming traffic. Here's why you should prioritize implementing health checks and probes:
-
Liveness probes:
This check determines if a pod is still running and healthy. If a liveness probe fails, the load balancer will remove the pod from the load balancing pool.
-
Startup probes:
This check ensures that only fully initialized pods are included in the load-balancing pool and prevents premature traffic. Thus, improving user experience and resource efficiency.
-
Readiness probes:
This check determines if a pod is ready to receive traffic. Failing a readiness probe prevents the load balancer from directing traffic to the pod.
By configuring your Kubernetes load balancer with health checks and probes, you can keep your application running and prevent your resources from being wasted.