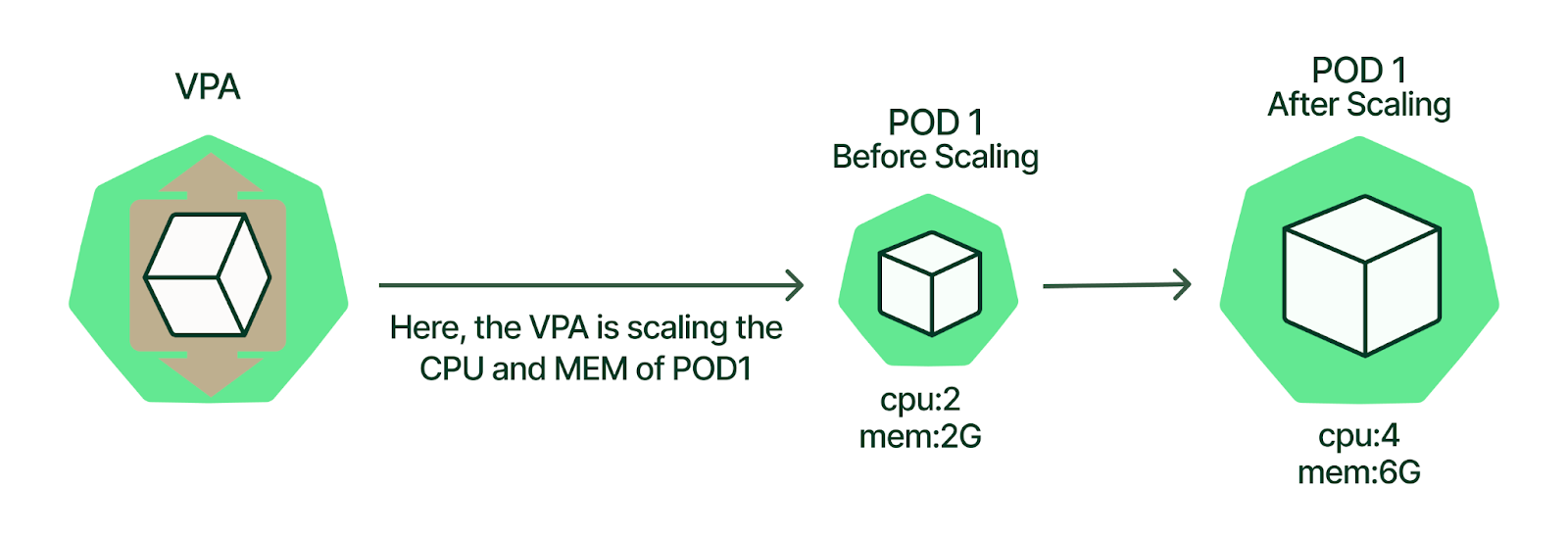
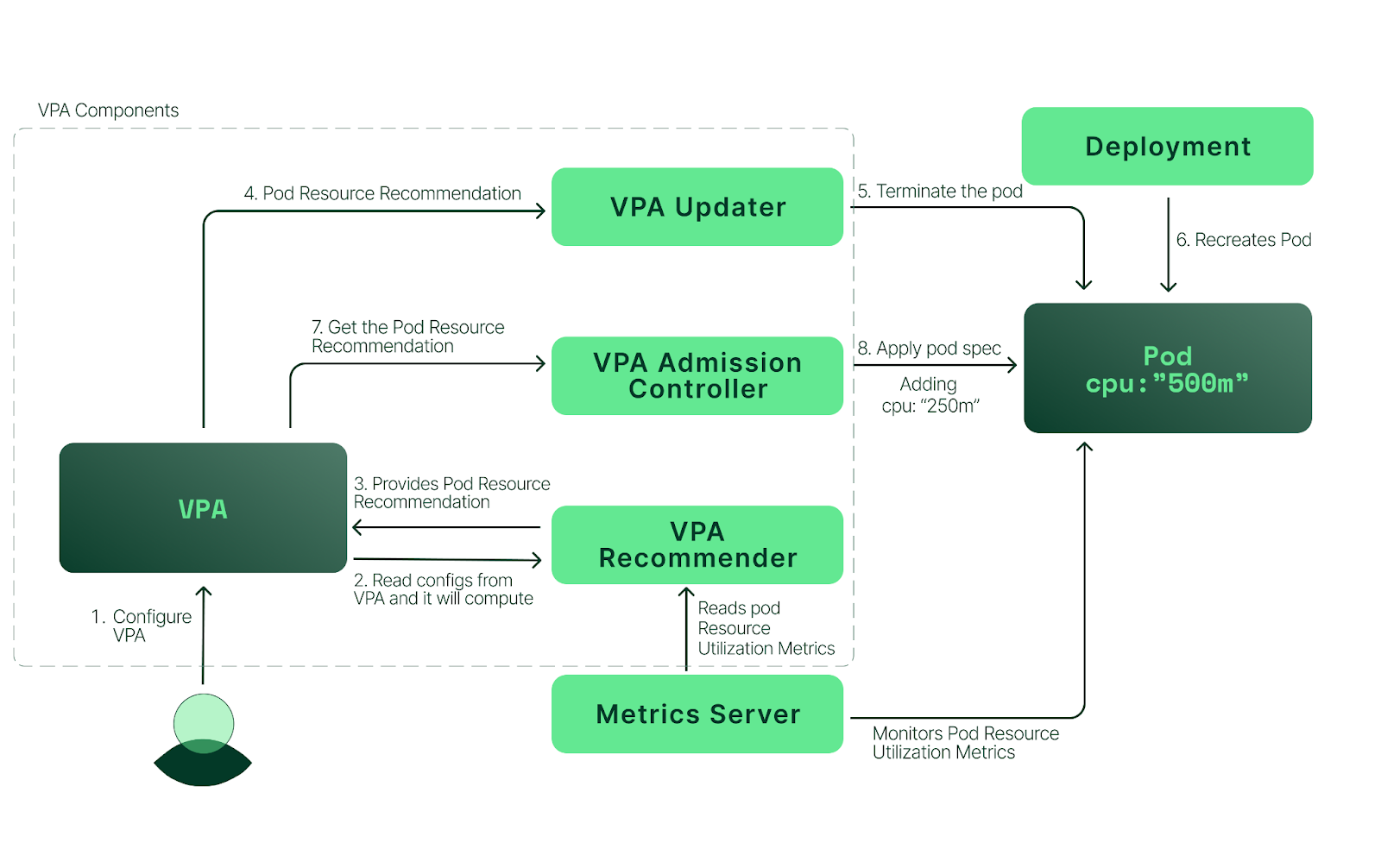
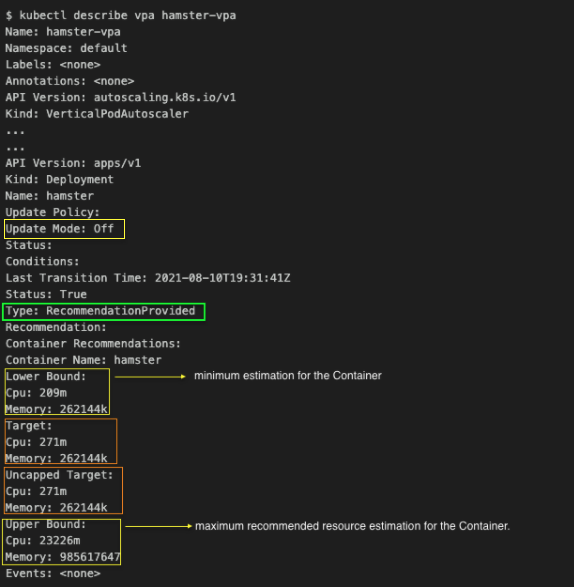
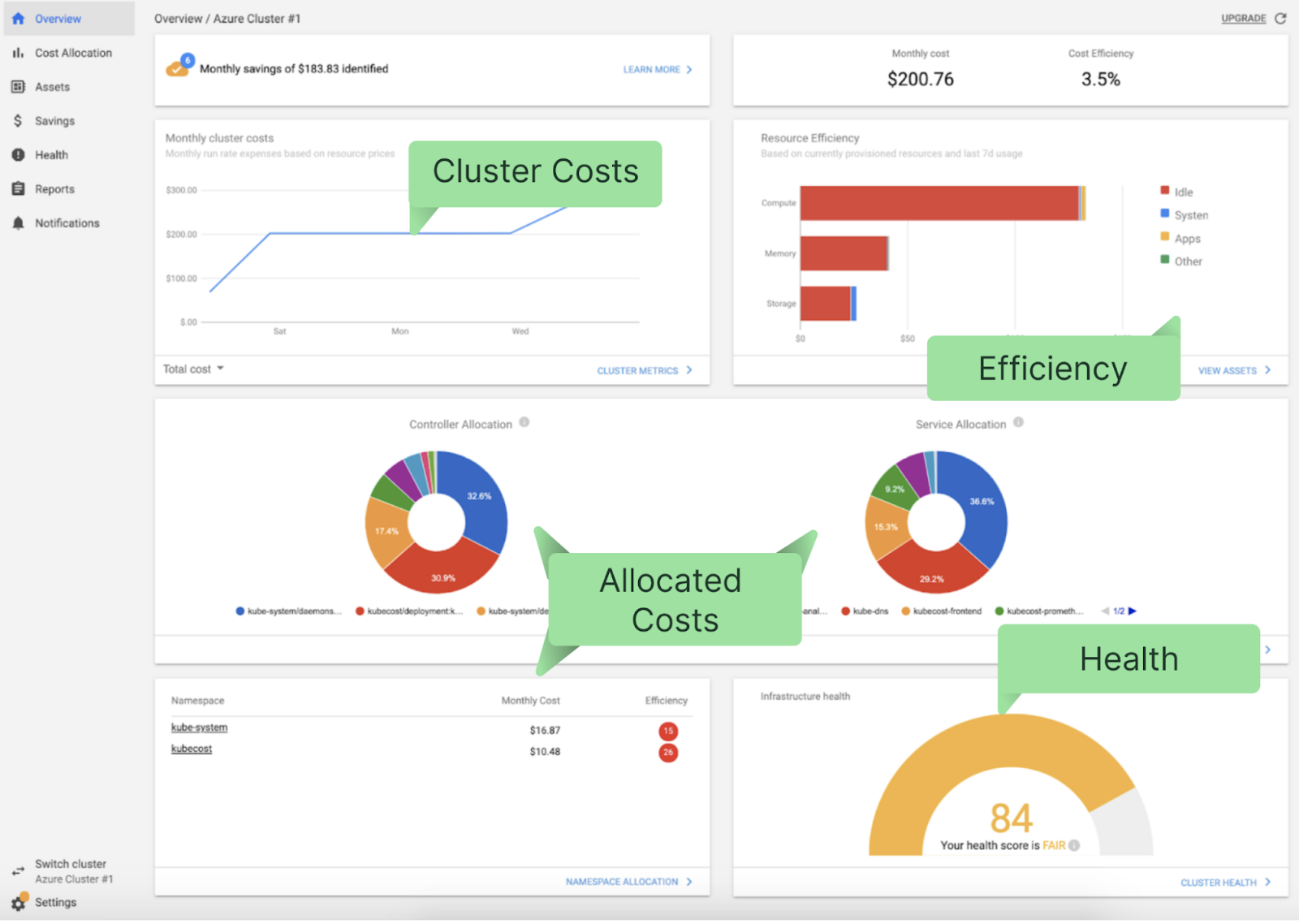
Now that we’ve reviewed VPA concepts, let’s look at a real-world example of how to install and use VPA. In this section, we’ll walk through a VPA deployment on Amazon Elastic Kubernetes Service (Amazon EKS) by following these high-level steps:
- Create an EKS cluster
- Install the metrics server
- Install the VPA
- Demo: example of VPA
Create an EKS Cluster:
To begin, we create an EKS cluster on AWS. There are multiple ways of doing this, but in this article, we will use “eksctl”, a simple CLI tool that AWS recommends. To learn more about “eksctl”, refer to the official eskctl website
Make sure you have the active AWS account configured in your local workstation/laptop. If not, please refer to this AWS doc. Once you have your account configured, create the below file and run the below command to create the EKS cluster:
$ cat eks.yaml
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: my-cluster
region: us-east-1
version: "1.20"
availabilityZones:
- us-east-1a
- us-east-1b
managedNodeGroups:
- name: general
labels:
role: general
instanceType: t3.medium
minSize: 1
maxSize: 10
desiredCapacity: 1
volumeSize: 20
Create the cluster:
$ eksctl create cluster -f eks.yaml
Verify that you can connect to the cluster:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 443/TCP 13m
Install the metrics server
Now we have the EKS cluster; the next step is to install the metrics server on it. We can confirm whether it is already installed by running the below commands:
$ kubectl get apiservice | grep -i metrics
If there is no output, we don't have a metrics server configured in our EKS cluster. We also can use the below command to see if we have metrics available:
$ kubectl top pods -n kube-system
error: Metrics API not available
Let’s install the metrics server. Clone the below repo:
$ git clone --branch v1.0.0 git@github.com:nonai/k8s-example-files.git
Apply the changes on the entire files as shown below:
$ kubectl apply -f .
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
Verify the deployment:
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
aws-node-8g4wk 1/1 Running 0 29m
coredns-86d9946576-g49sk 1/1 Running 0 38m
coredns-86d9946576-kxw4h 1/1 Running 0 38m
kube-proxy-64gjd 1/1 Running 0 29m
metrics-server-9f459d97b-j4mnr 1/1 Running 0 117s
List API services and check for metrics server:
$ kubectl get apiservice |grep -i metrics
v1beta1.metrics.k8s.io kube-system/metrics-server True 2m26s
List services in the kube-system namespace:
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.100.0.10 53/UDP,53/TCP 40m
metrics-server ClusterIP 10.100.152.164 443/TCP 2m58s
We can access metrics API directly:
$ kubectl get --raw /apis/metrics.k8s.io/v1beta1 | jq
Use kubectl to get metrics:
$ kubectl top pods -n kube-system
NAME CPU(cores) MEMORY(bytes)
aws-node-8g4wk 4m 40Mi
coredns-86d9946576-g49sk 2m 8Mi
coredns-86d9946576-kxw4h 2m 8Mi
kube-proxy-64gjd 1m 11Mi
metrics-server-9f459d97b-j4mnr 3m 17Mi