Autoscaling is one of the most compelling features of the Kubernetes platform. Once configured correctly, it saves administrators time, prevents performance bottlenecks, and helps avoid financial waste. However, setting up autoscaling requires knowledge of numerous configuration parameters that can confuse even experienced Kubernetes administrators—that’s why we created this guide explaining autoscaling in detail. We have dedicated one article to each type of autoscaling, and included configuration instructions and YAML file examples along the way.
Learn the three dimensions of Kubernetes autoscaling, VPA, HPA and Cluster Autoscaler by following examples and best practices.
Kubecost.com is moving to Apptio.com — read more about what's next!
Kubernetes Autoscaling
Comprehensive Kubernetes cost monitoring & optimization
The three dimensions of Kubernetes autoscaling
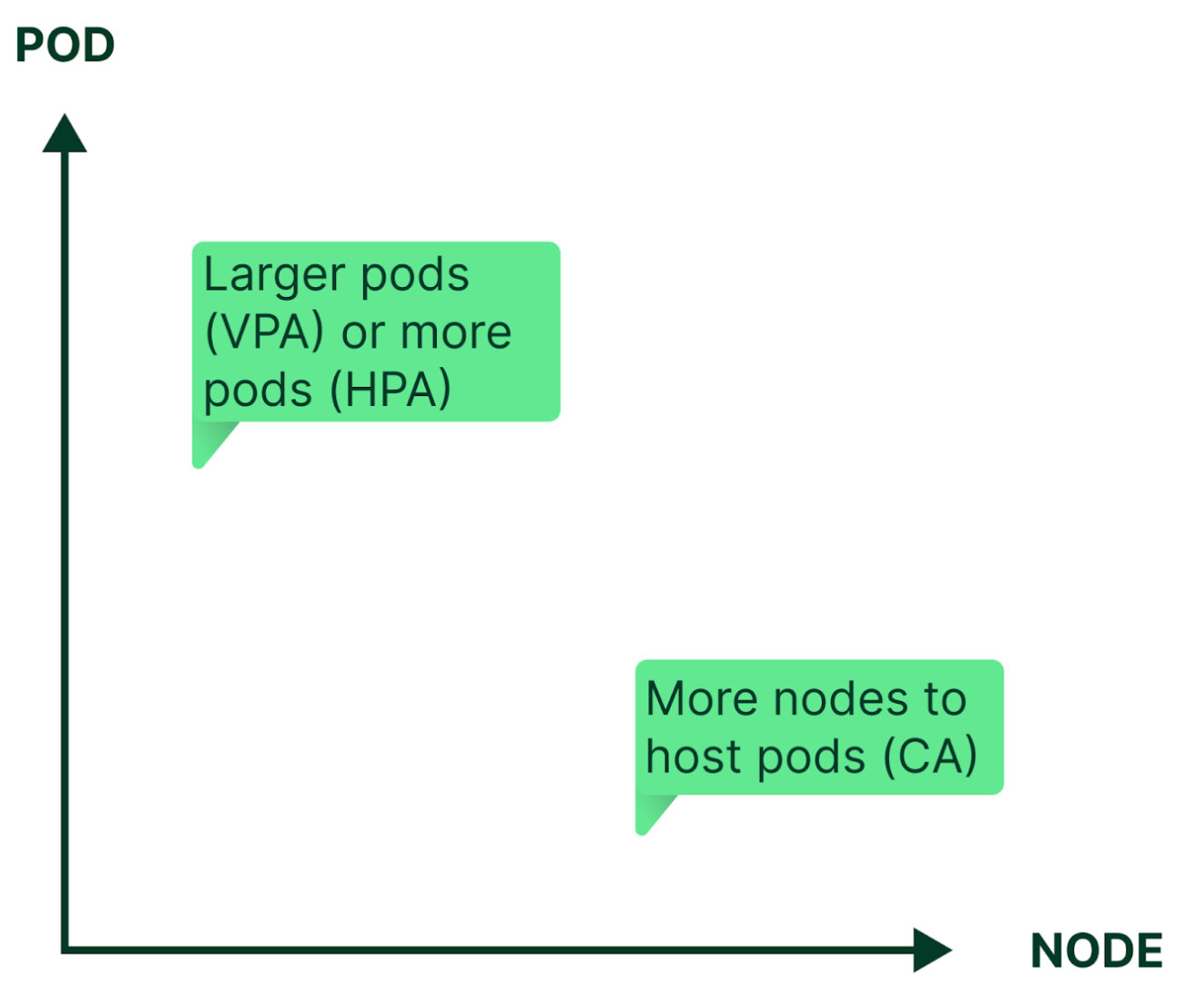
Autoscaling eliminates the need for constant manual reconfiguration to match changing application workload levels. Kubernetes can autoscale by adjusting the capacity (vertical autoscaling) and number (horizontal autoscaling) of pods, and/or by adding or removing nodes in a cluster (cluster autoscaling).
There are two types of pod autoscalers: Vertical Pod Autoscaler (VPA) can either increase or decrease the CPU and memory allocated to each pod, while the Horizontal Pod Autoscaler (HPA) can replicate or terminate pods, thus affecting the total pod count. Affecting the cluster capacity as a whole, the Cluster Autoscaler (CA) adds or removes nodes dedicated to the cluster to provide the appropriate amount of computing resources needed to host the desired workloads. In combination, the three dimensions of autoscaling help strike—in near-real-time—the delicate balance between preventing performance bottlenecks or outages and avoiding overprovisioning.
Why autoscale?
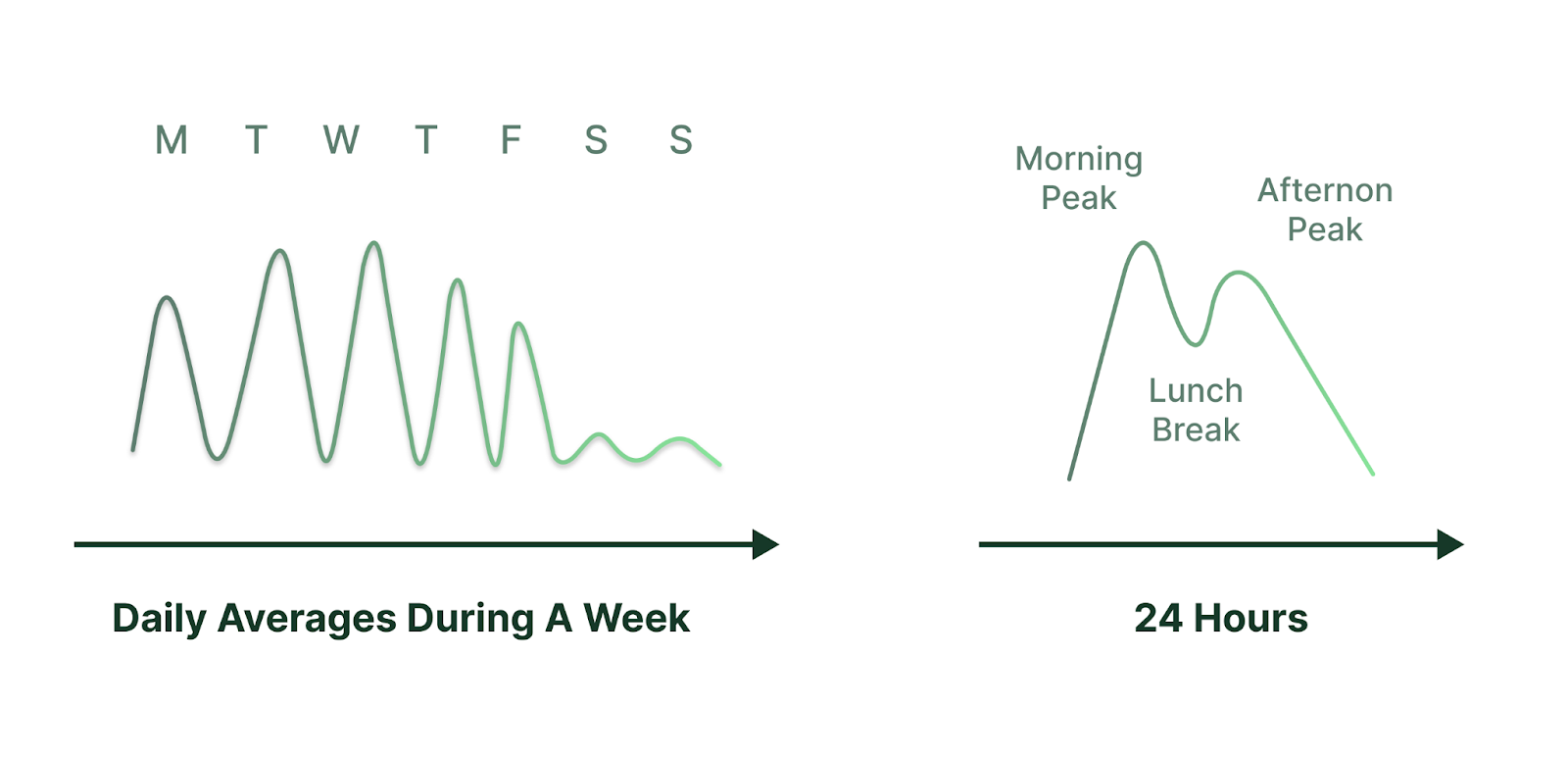
Most application workloads have daily, weekly, and seasonal rhythms driven by user activity. This variability can either cause application performance to degrade due to resource constraints, or result in unnecessary spending due to overprovisioning.
Kubecost + StormForge = Automated K8s Cost Optimization
For example, let’s say the peak hours for enterprise productivity applications are mid-morning and mid-afternoon in a given timezone when employees are at their desks, while they are close to idle on weekends and holidays. Some enterprise financial applications are most active near the end of each calendar quarter, when financial statements are issued. In contrast, some payroll processing applications are often busy twice a month to issue paychecks, and batch processing applications are busy during the overnight hours when they are typically scheduled to run. There are also seasonal traffic patterns such as online retail shopping on Black Friday or Mother’s Day. Other increases in activity may result from a one-time event, like an approaching hurricane drawing residents to news websites.
Administrators of application infrastructure must prepare their systems to provision capacity within seconds to respond to both predictable and unexpected changes in activity, and remember to remove the capacity when it’s no longer needed. That’s where autoscaling comes in: It automates the process of adding and removing capacity as the workload varies which would otherwise be manual.
K8s clusters handling 10B daily API calls use Kubecost
Measurement and allocation
It’s easy to manage a Kubernetes cluster by overprovisioning: say, if it hosts only a single application and money is no object. But that’s not the reality, especially when it comes to large Kubernetes deployments shared by dozens of tenants who each have limited budgets. In this more common scenario, the cluster costs must be divided fairly and accurately between the teams, projects, and applications that share the Kubernetes resources.
The cost allocation report for a Kubernetes cluster with a static configuration and two tenants with well-labeled resources is straightforward to calculate. But once you introduce autoscaling into the equation, it becomes impossible for a person to allocate the costs of a Kubernetes cluster to dozens of tenants as autoscaling changes the underlying cluster configuration every minute.
It helps ease the administrative burden if you dedicate a Kubernetes namespace to each tenant, but the challenge of measuring the respective usage of dedicated—and especially shared—resources remains complicated. A fair allocation of costs must consider each tenant’s pro-rated usage of the cluster resources over time, including CPU, GPU, memory, disk, and network.
The Kubecost open source project was conceived to meet this very challenge—providing a simple way to measure cluster resource consumption for applications and teams, and breaking down their respective costs by Kubernetes concepts such as deployment, service, namespace, and label for reporting. Kubecost is always free to use within one cluster of any size and can be downloaded here.
Chapters
We have organized this guide in the following articles:
Chapter 1: Kubernetes Vertical Pod Autoscaler (VPA)
Chapter 2: Kubernetes Horizontal Pod Autoscaler (HPA)
Chapter 3: Kubernetes Cluster Autoscaler (CA)
Each chapter includes detailed explanations of the feature, along with configuration examples so you can see them implemented in practice.
Learn how to manage K8s costs via the Kubecost APIs