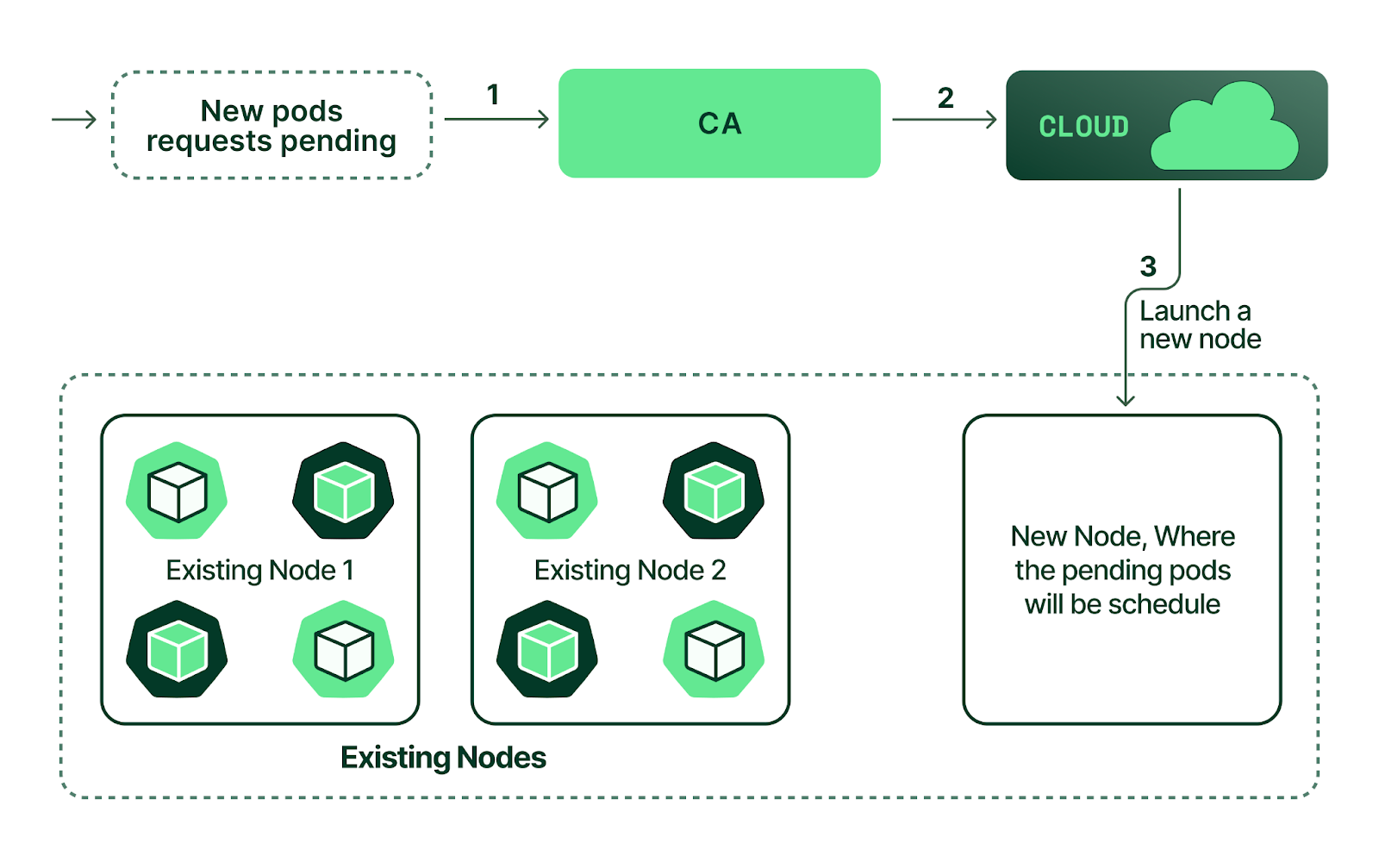
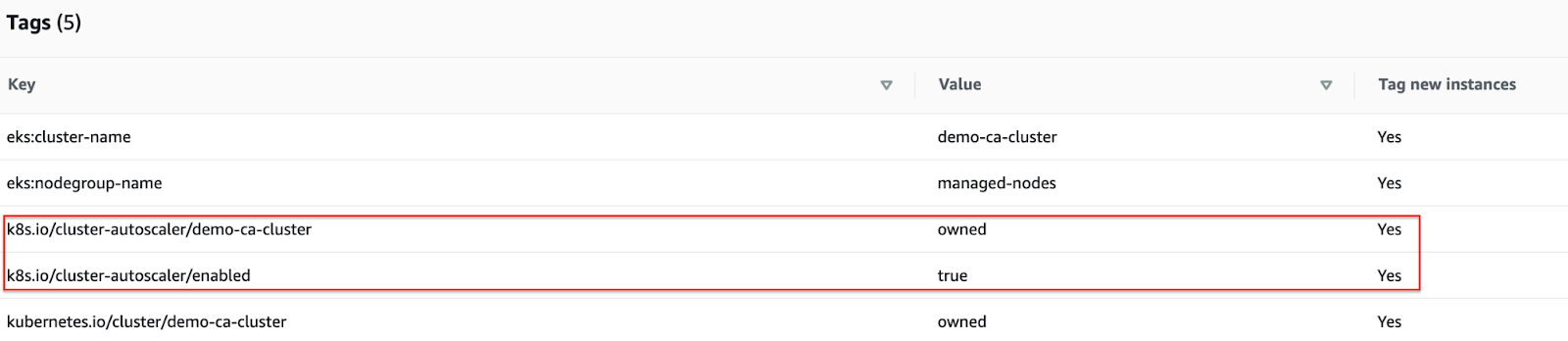
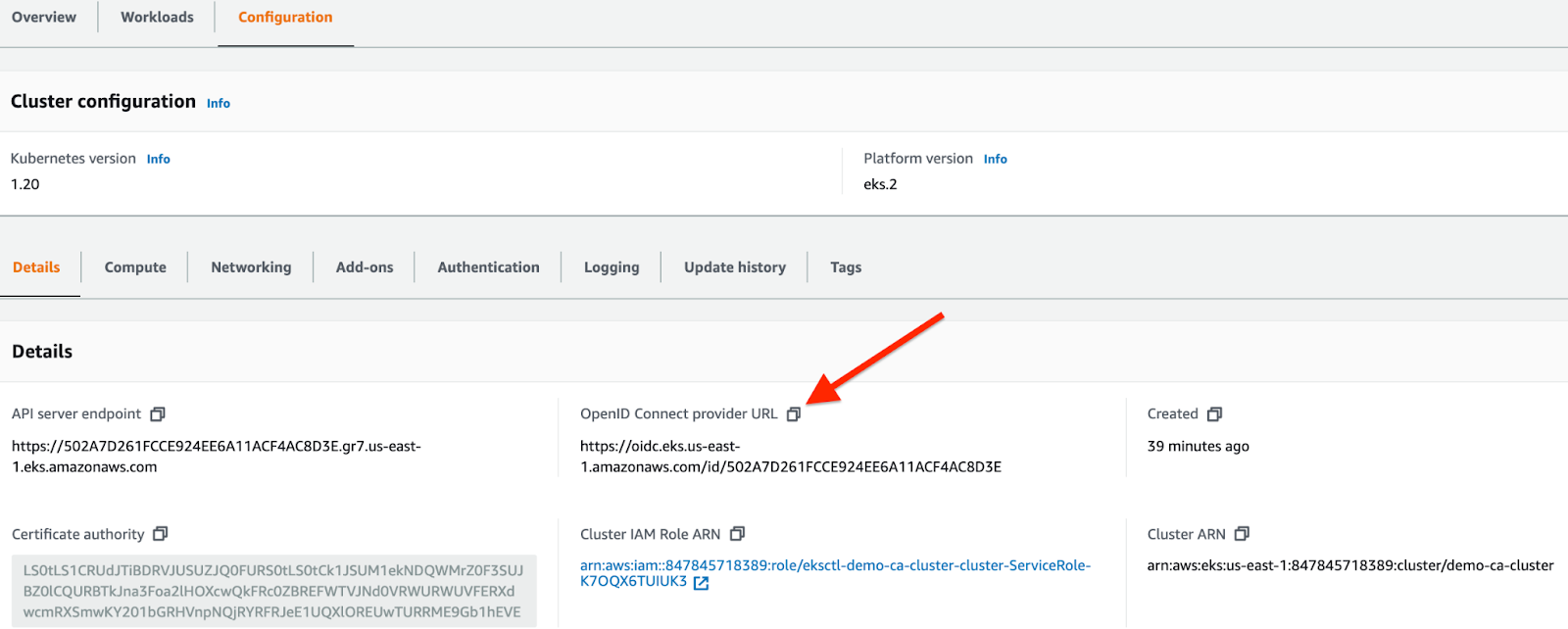
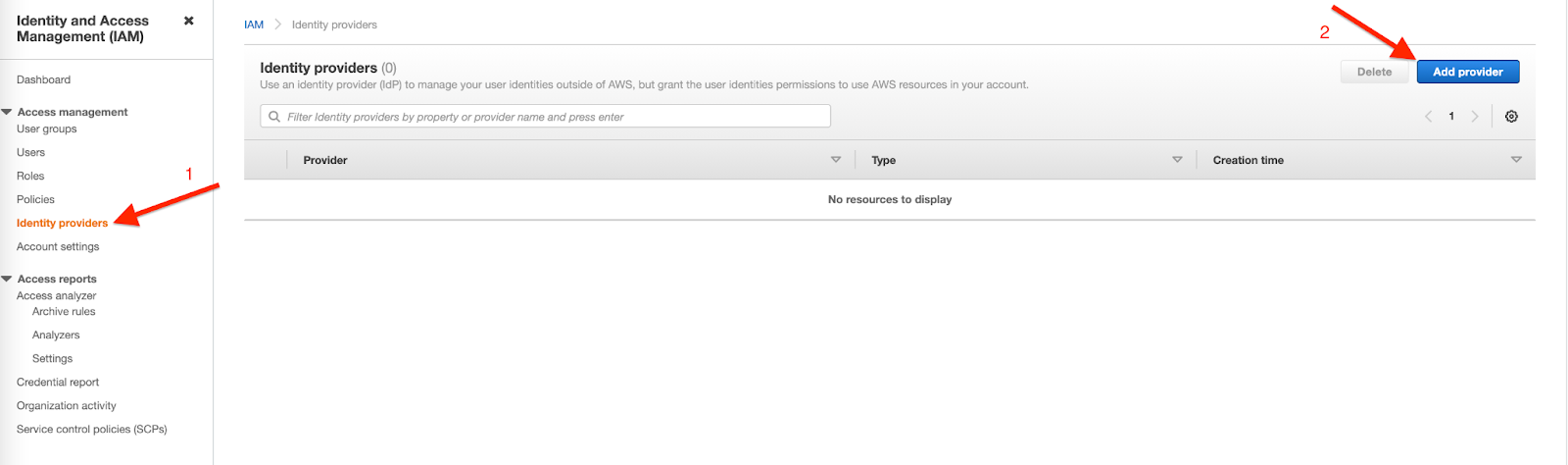
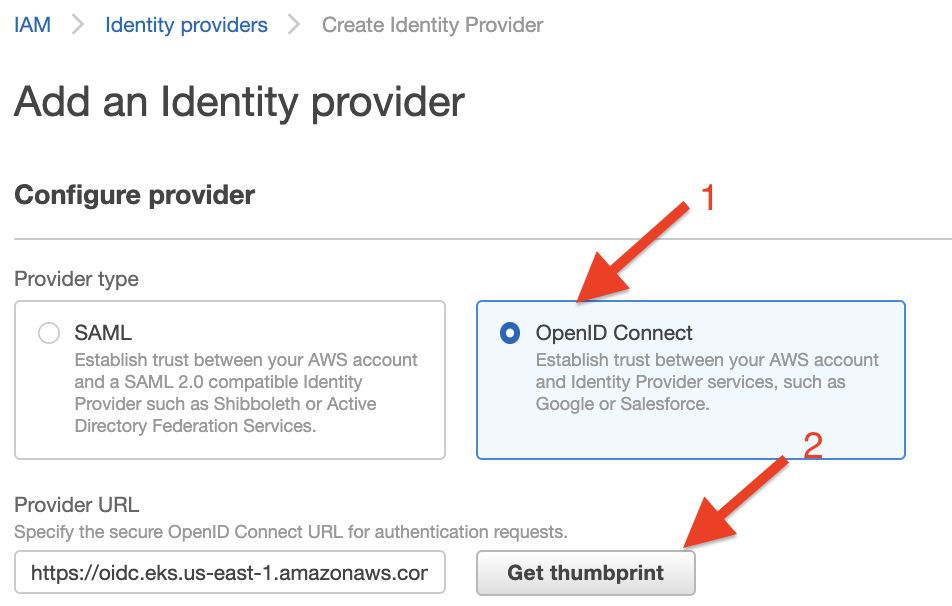
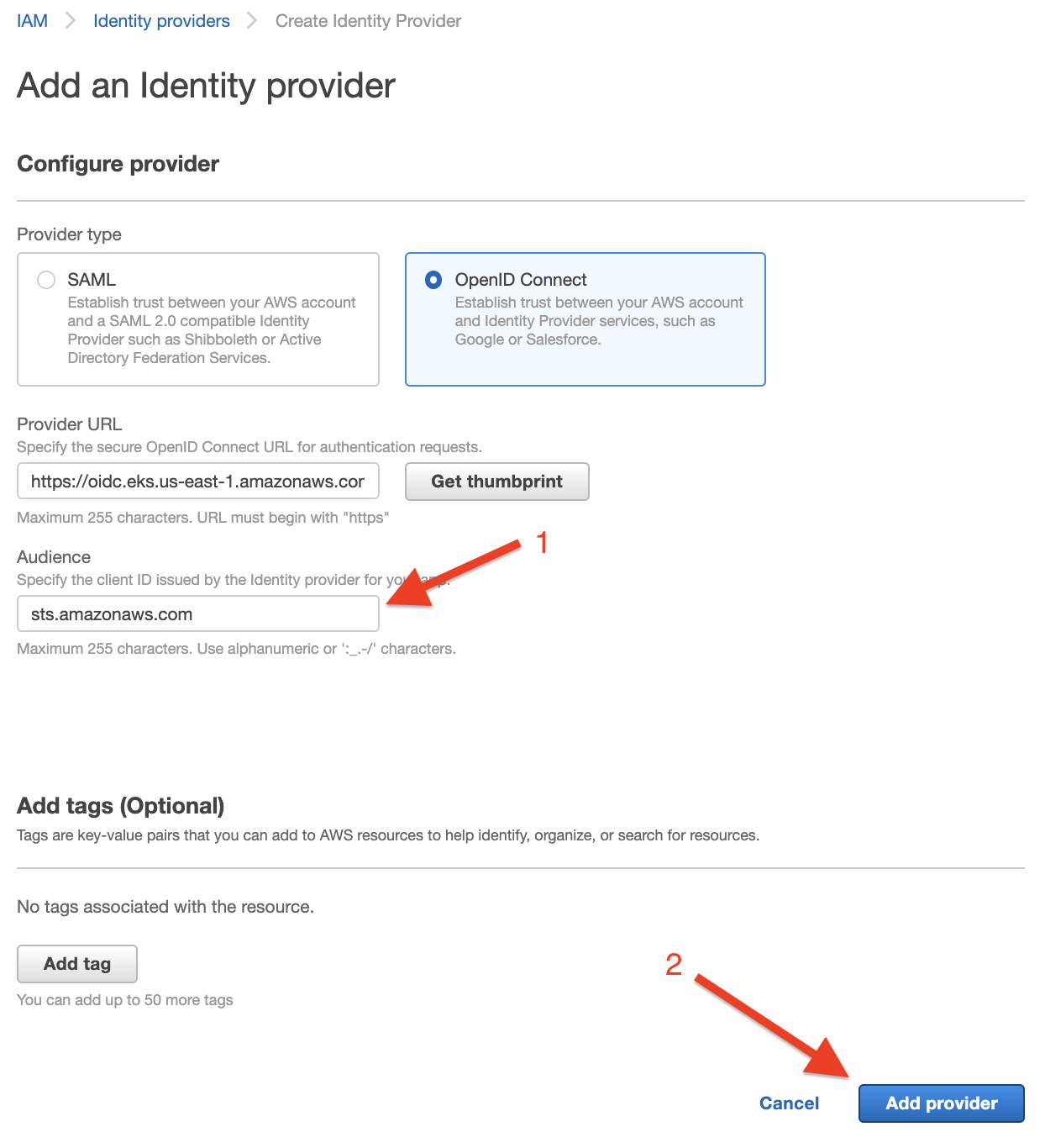
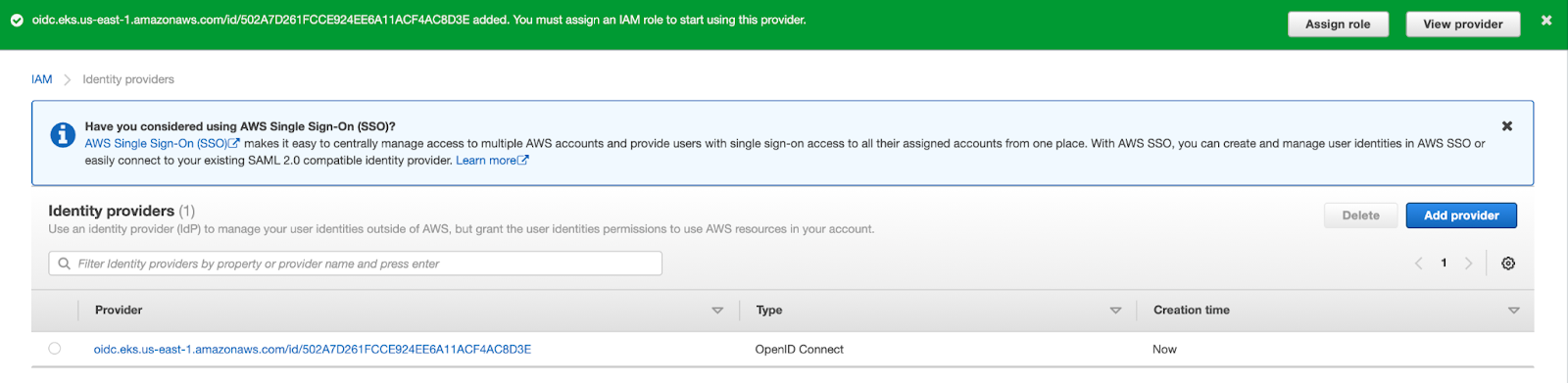
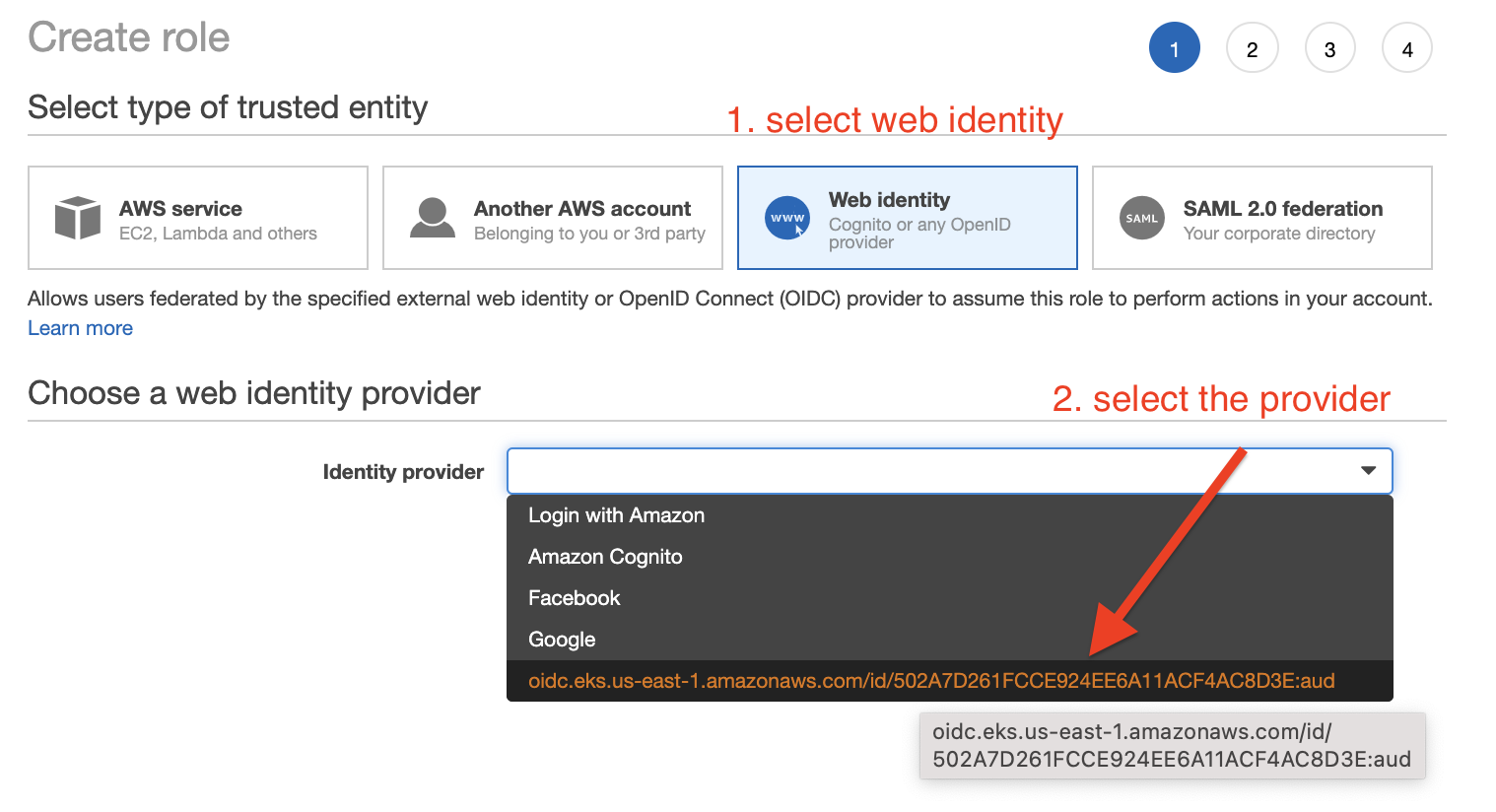
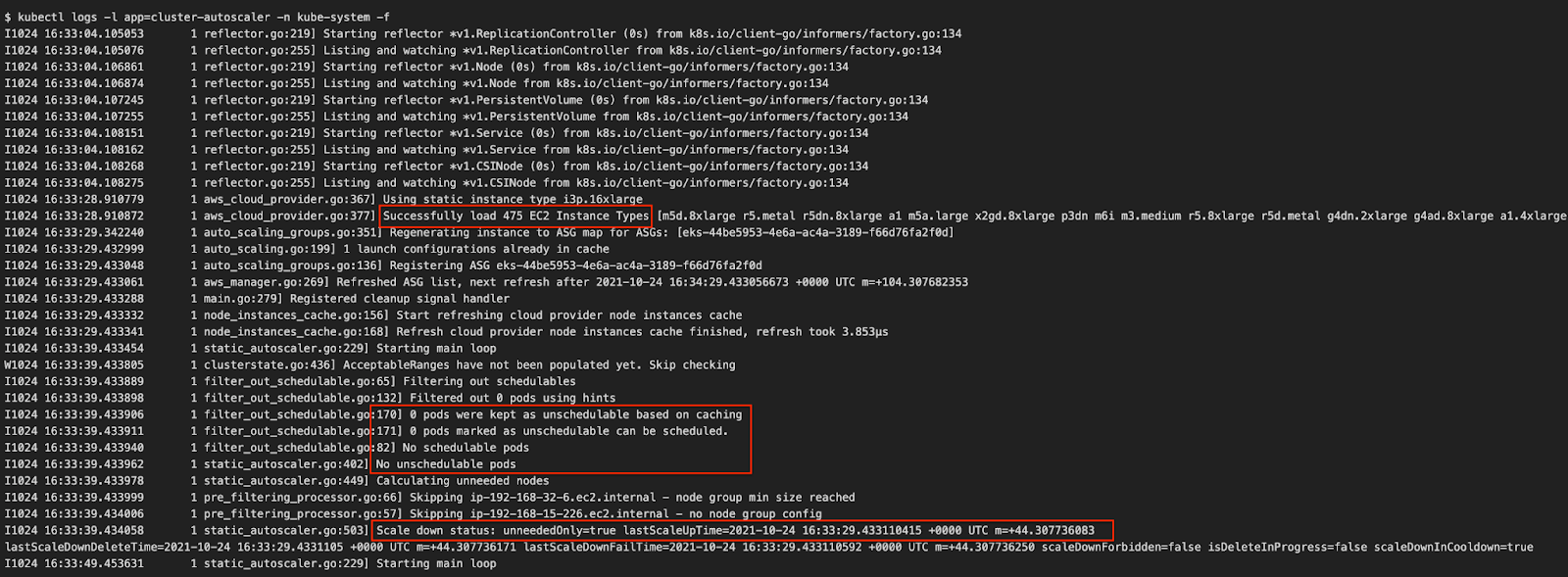
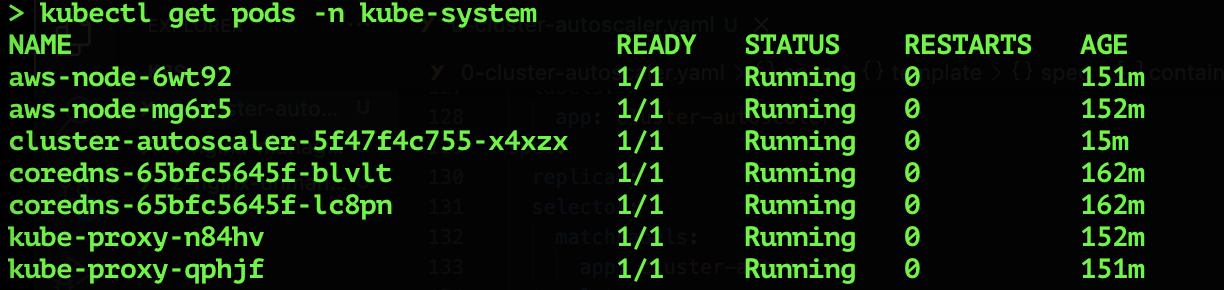
Congratulations! You have deployed the Cluster Autoscaler successfully.
Here, you see two nodes in the cluster where one node is under a managed group and another under an unmanaged group. This configuration allows us to test the Cluster Autoscaler functionality later in our exercise. Next, we will deploy Nginx as a sample application deployment to exercise autoscaling and observe CA’s actions.
STEP 7: Create an Nginx deployment to test autoscaler functionality
We are going to create two deployments: one for the managed node group, and another deployment for the unmanaged node group.
Manage node group deployment:
Create a configuration file based on the content below:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-managed
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx-managed
template:
metadata:
labels:
app: nginx-managed
spec:
containers:
- name: nginx-managed
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- managed-nodes
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-managed
topologyKey: kubernetes.io/hostname
namespaces:
- default
Note: The above configurations make use of nodeAffinity to select the node group with the label “role=managed-nodes” to help control where the scheduler provisions the pods.
Apply the changes:
$ kubectl apply -f 1-nginx-managed.yaml
deployment.apps/nginx-managed created
Unmanaged Node group Deployment:
For the unmanaged node group, create a configuration file using the content below
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-unmanaged
namespace: default
spec: replicas: 2
selector:
matchLabels:
app: nginx-unmanaged
template:
metadata:
labels:
app: nginx-unmanaged
spec:
containers:
- name: nginx-unmanaged
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- unmanaged-nodes
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-unmanaged
topologyKey: kubernetes.io/hostname
namespaces:
- default
Apply the changes
$ kubectl apply -f 2-nginx-unmanaged.yaml
deployment.apps/nginx-unmanaged created
Check the status of the pods.
$ kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
nginx-managed-7cf8b6449c-mctsg 1/1 Running 0 60s
nginx-managed-7cf8b6449c-vjvxf 0/1 Pending 0 60s
nginx-unmanaged-67dcfb44c9-gvjg4 0/1 Pending 0 52s
nginx-unmanaged-67dcfb44c9-wqnvr 1/1 Running 0 52s
Now, you can see two of the four pods are running because we have only two nodes in the cluster. Please note that we have used a pod AntiAffinity configuration to prevent Kubernetes from provisioning multiple pods of this deployment on the same node (thereby avoiding the need for the additional capacity required to demonstrate CA’s functionality).
The Cluster Autoscaler will check the state of the pods, discover that some are in a “pending” state, and try to provision new nodes in the cluster. In a few minutes, you will see a third node provisioned.