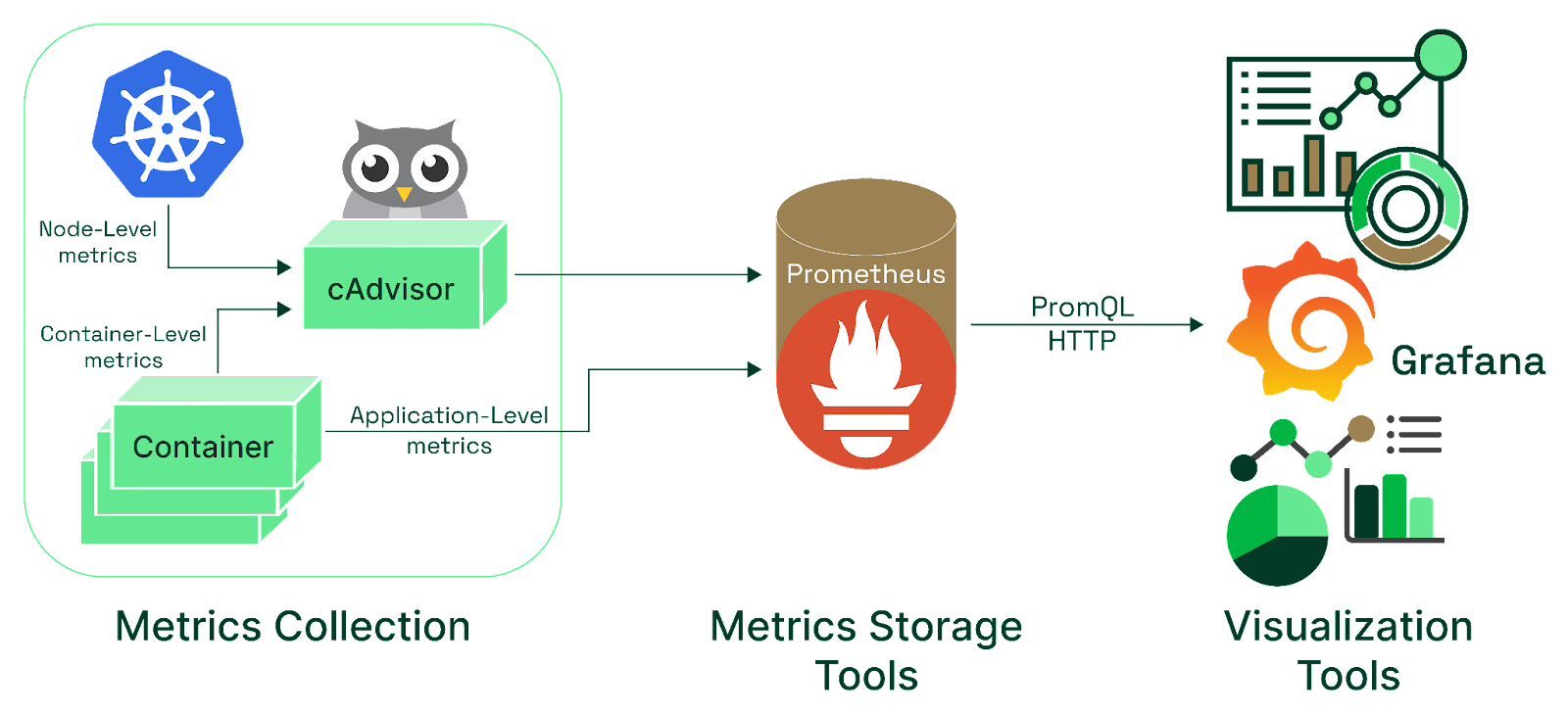
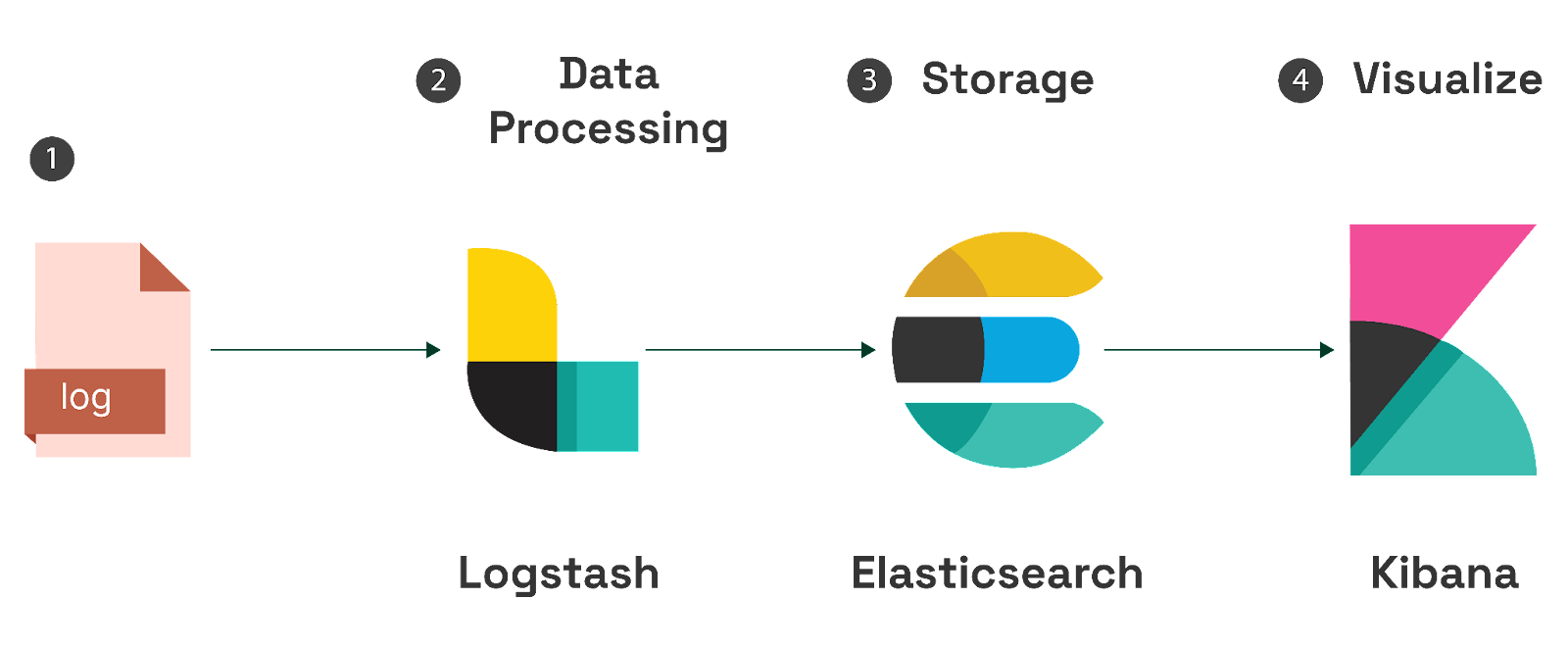
AI stands out for its potential impact on the future of Kubernetes performance monitoring. AI brings a new level of sophistication in detecting anomalies, providing predictive insights, and conducting root cause analysis.
AI-enabled tools ecosystems
Tools like Dynatrace, New Relic, and Datadog have started integrating AI capabilities, offering more intelligent monitoring solutions. Each tool provides out-of-the-box AI functionalities specifically tailored for Kubernetes, enhancing its monitoring through advanced anomaly detection, predictive insights, and efficient root cause analysis. Integrating these tools into your Kubernetes environment can significantly improve the way you monitor and manage the performance and health of your applications and infrastructure.
Dynatrace
Dynatrace offers seamless observability in cloud-native environments with features like automated anomaly detection, performance analysis, and end-to-end transaction tracing, all of which are crucial for dynamic Kubernetes environments.
Dynatrace provides an intelligent platform with multiple modules. One of these modules is Davis AI, which is designed for automatic root cause analysis. It excels in detecting anomalies, correlating them with other events, and identifying the likely cause of issues. Another module is OneAgent, which is used as a monitoring solution to simplify data collection across the entire IT infrastructure, including Kubernetes environments.
New Relic
New Relic's AI component, called New Relic Applied Intelligence, offers automatic anomaly detection, an intelligent grouping of all related warnings and issues (which New Relic calls “noise reduction”) and suggestions of relevant and actionable decisions based on your usage and historical data. It helps reduce time-wasting and enhances focus on critical issues.
New Relic's Kubernetes integration includes monitoring Kubernetes events, nodes, pods, and container performance, providing a comprehensive view of your Kubernetes cluster's health and performance through a multidimensional representation of a Kubernetes cluster. This allows you to drill down into Kubernetes data and gain insights into your containers' and pods' performance and health.
Datadog
Datadog incorporates AI and machine learning for anomaly and outlier detection, making it easier to spot issues that deviate from standard patterns.
Datadog stands out because it can correlate logs and metrics, providing a unified view of what's happening in your Kubernetes environment. It also offers live container monitoring, which enhances dynamic container orchestration. In addition to the current events view, Datadog provides forecasting algorithms to alert users about possible problems with sufficient time to address them and avoid issues altogether
Elastic Stack
Elastic has recently introduced an AI Assistant, which is still in beta. The Elastic AI Assistant uses generative AI, powered by OpenAI, to provide contextual insights that explain errors and messages and suggest remediation. It also has chat conversations with the AI Assistant to request, analyze, and visualize your data.
AI-driven techniques and use cases
This section explores the transformative impact of AI in Kubernetes monitoring. We'll examine key AI-driven techniques and tie them to offering products or use cases. These techniques show the growing importance of AI in performance monitoring.
Anomaly pattern detection
AI algorithms excel at pattern recognition, which means they can detect anomalies that might elude traditional threshold-based monitoring systems. Unlike static thresholds, AI can adapt to changes in the environment, learning from historical data to identify what constitutes normal behavior and what does not.
For example, in a scenario where a Kubernetes cluster experiences an unusual spike in resource usage, AI can quickly discern whether this spike is a regular occurrence (like a predictable increase in traffic every Monday morning) or an anomaly that needs investigation.
This is one of the basic AI monitoring use cases. Most AI monitoring tools offer anomaly detection features, including the tools discussed in the previous section.
Predictive insights
AI doesn't just react to current states—it can also predict future issues. By analyzing trends and patterns, AI can forecast potential resource shortages or predict when your system might hit its limits.
With predictive insights, you can preemptively scale resources during expected high-load periods or optimize your deployments before issues become critical. For instance, if AI predicts a resource crunch due to an upcoming marketing campaign, you can scale up in advance to ensure smooth performance. The Datadog tool is known for predictive analysis; its documentation claims that its forecast alerts could notify teams a week before disk space is expected to run out based on recent trends and seasonal patterns in that system's disk usage.
Root cause analysis
Kubernetes environments can be complex, and pinpointing the exact cause of a problem is often challenging when something goes wrong. AI enhances root cause analysis by sifting through vast amounts of data to identify the source of a problem.
A tool like New Relic is excellent at conducting AI-powered root cause analysis for issues detected in Kubernetes environments. For example, as shown in this demonstration, the tool correlated several alerts to analyze a slow web portal response issue. The analysis revealed a recent database query optimization as the root cause, which was validated by deployment timelines and error rates. This showcases New Relic's efficiency in pinpointing issues and guiding swift resolution; check out its hands-on labs for more info.
Continuous improvement and learning
One of the most exciting aspects of AI in performance monitoring is its ability to learn and improve continuously. Over time, these AI systems become more adept at understanding the specific nuances of your Kubernetes environment.
As your Kubernetes setup changes and grows, the AI system adapts, ensuring that monitoring remains effective and relevant. For instance, an AI-based monitoring tool in a Kubernetes environment can learn over time that the streaming service scales out during peak hours and major event broadcasts and scales back in after the events.
As this technology continues to evolve, it will undoubtedly open new avenues for optimization and stability in Kubernetes operations.