Understand system behavior and the importance of granularity
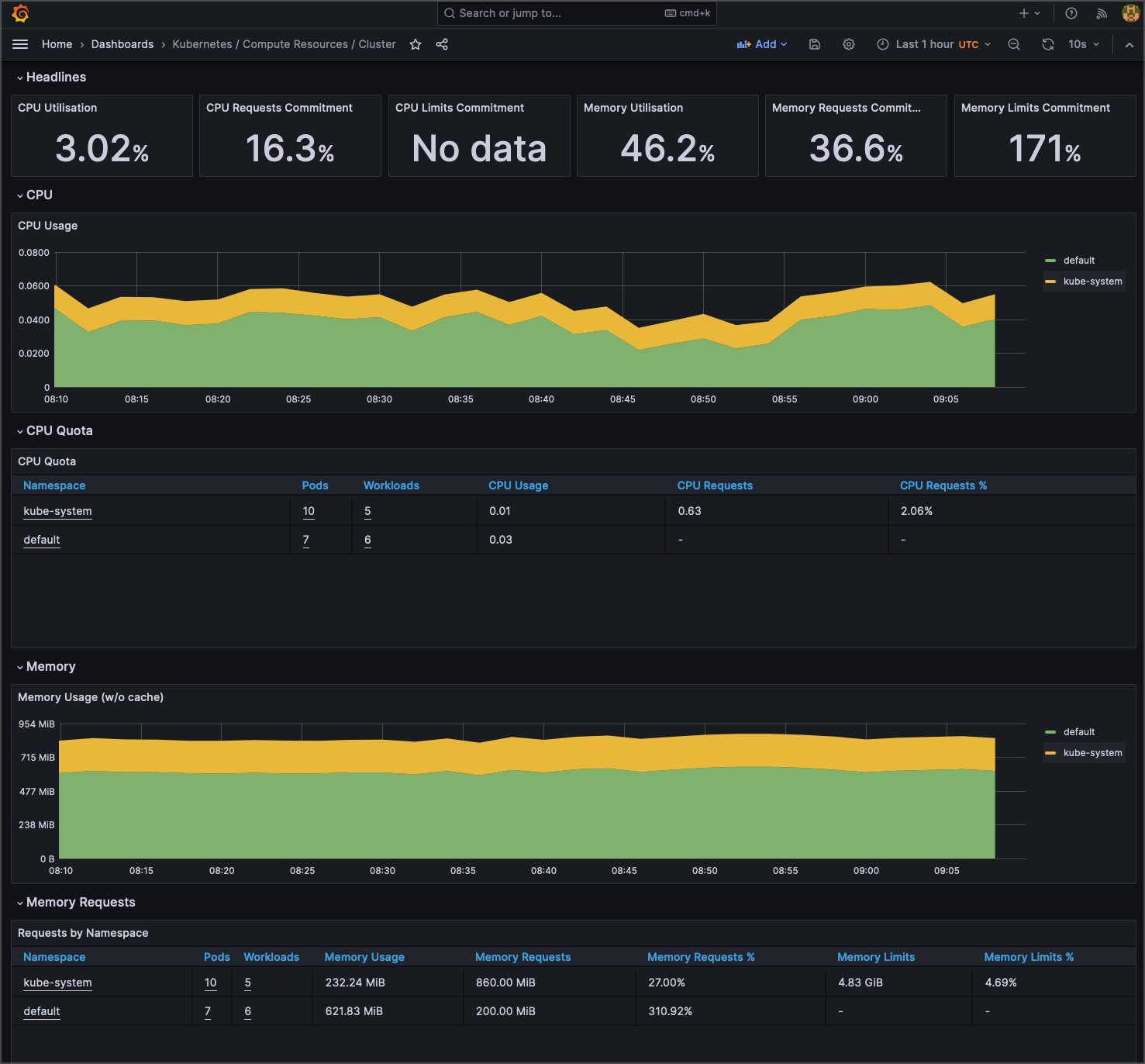
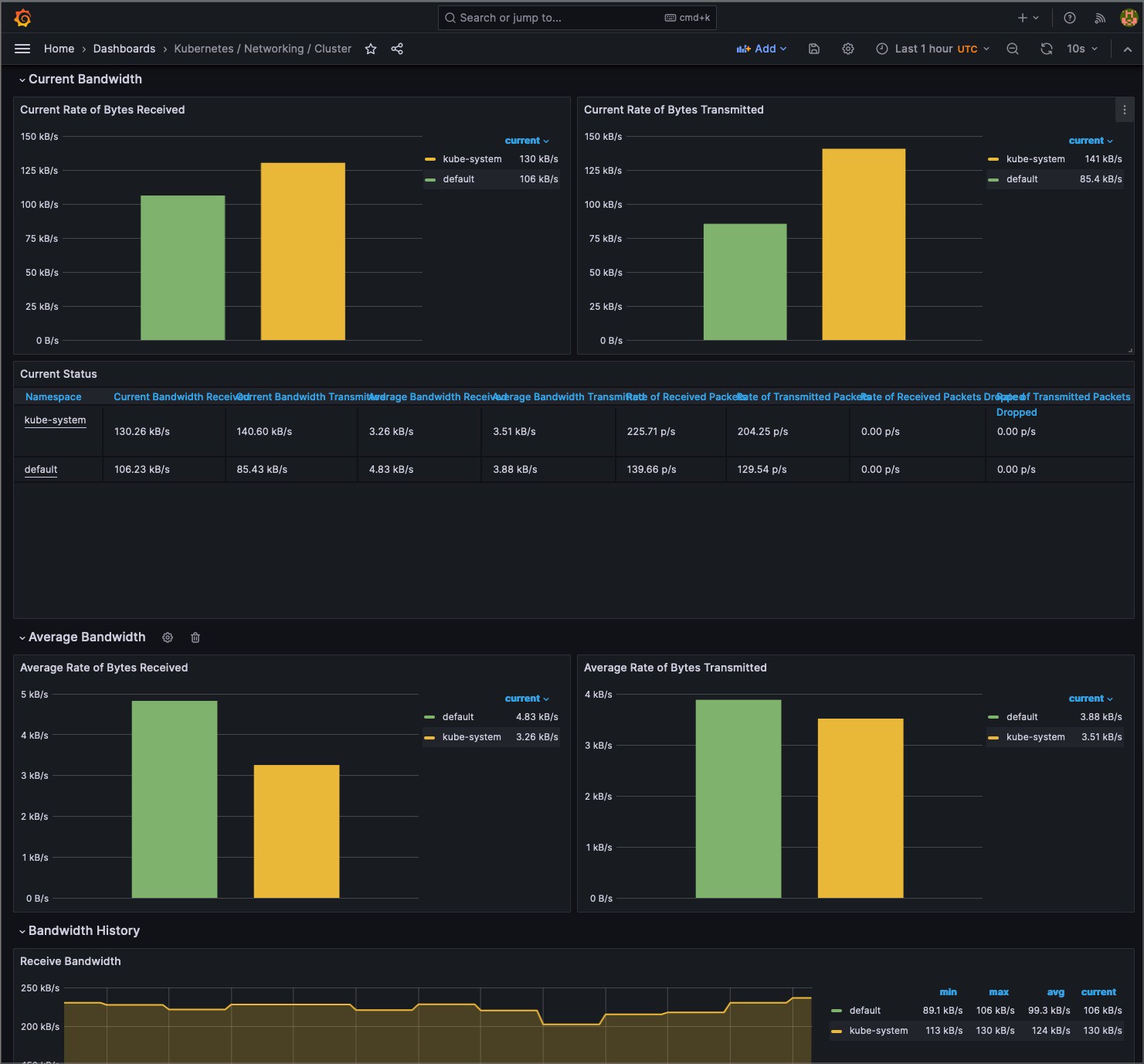
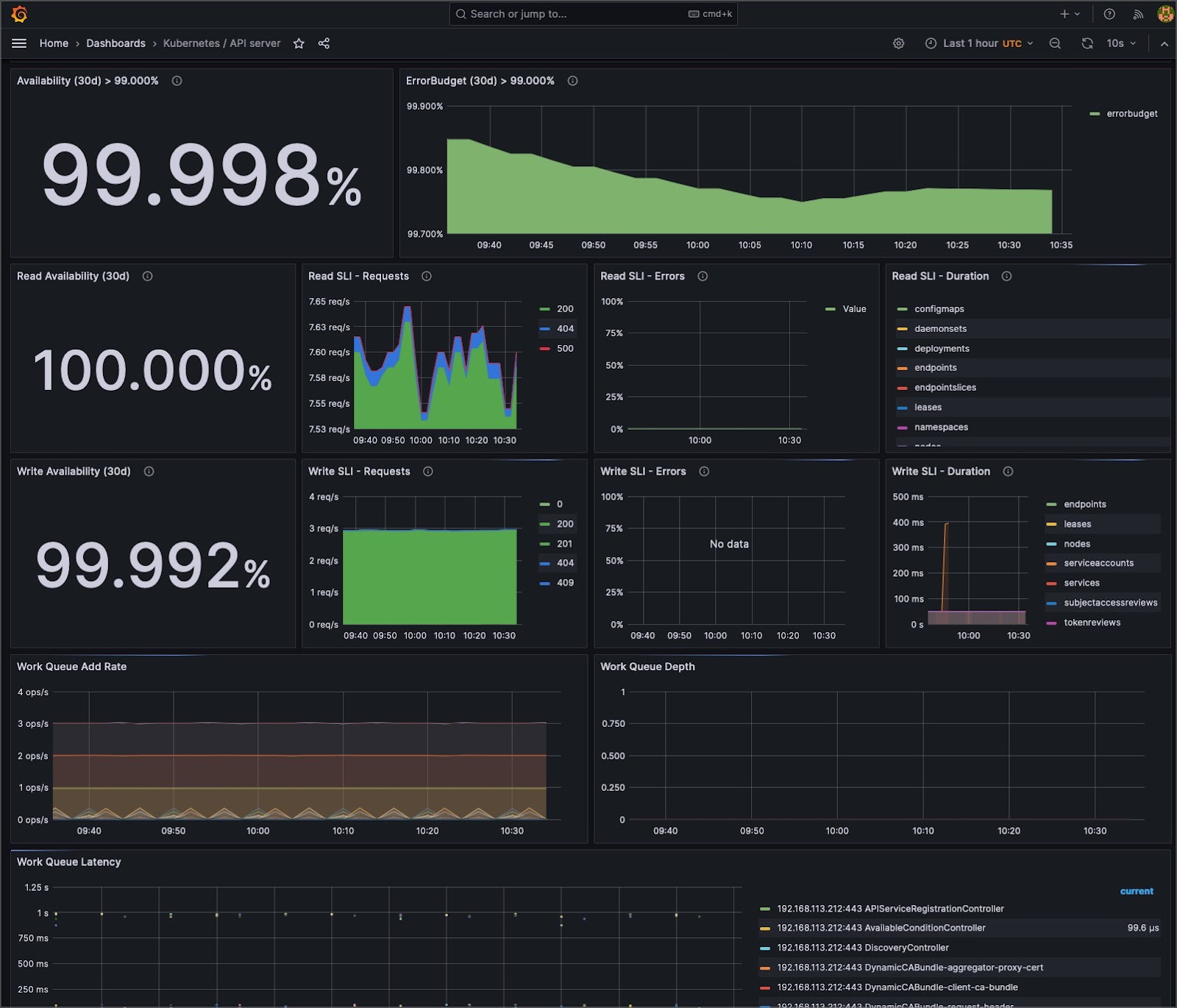
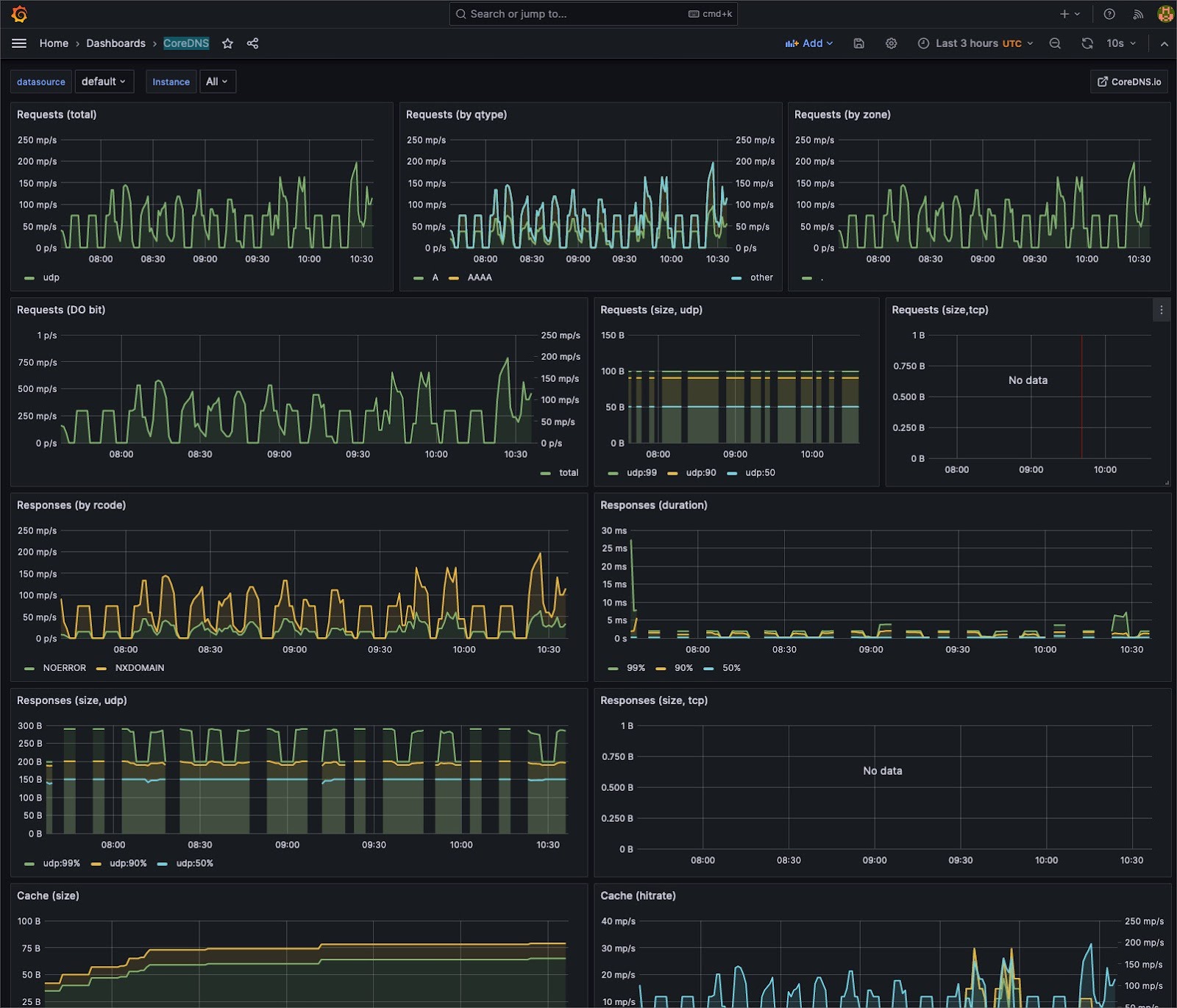
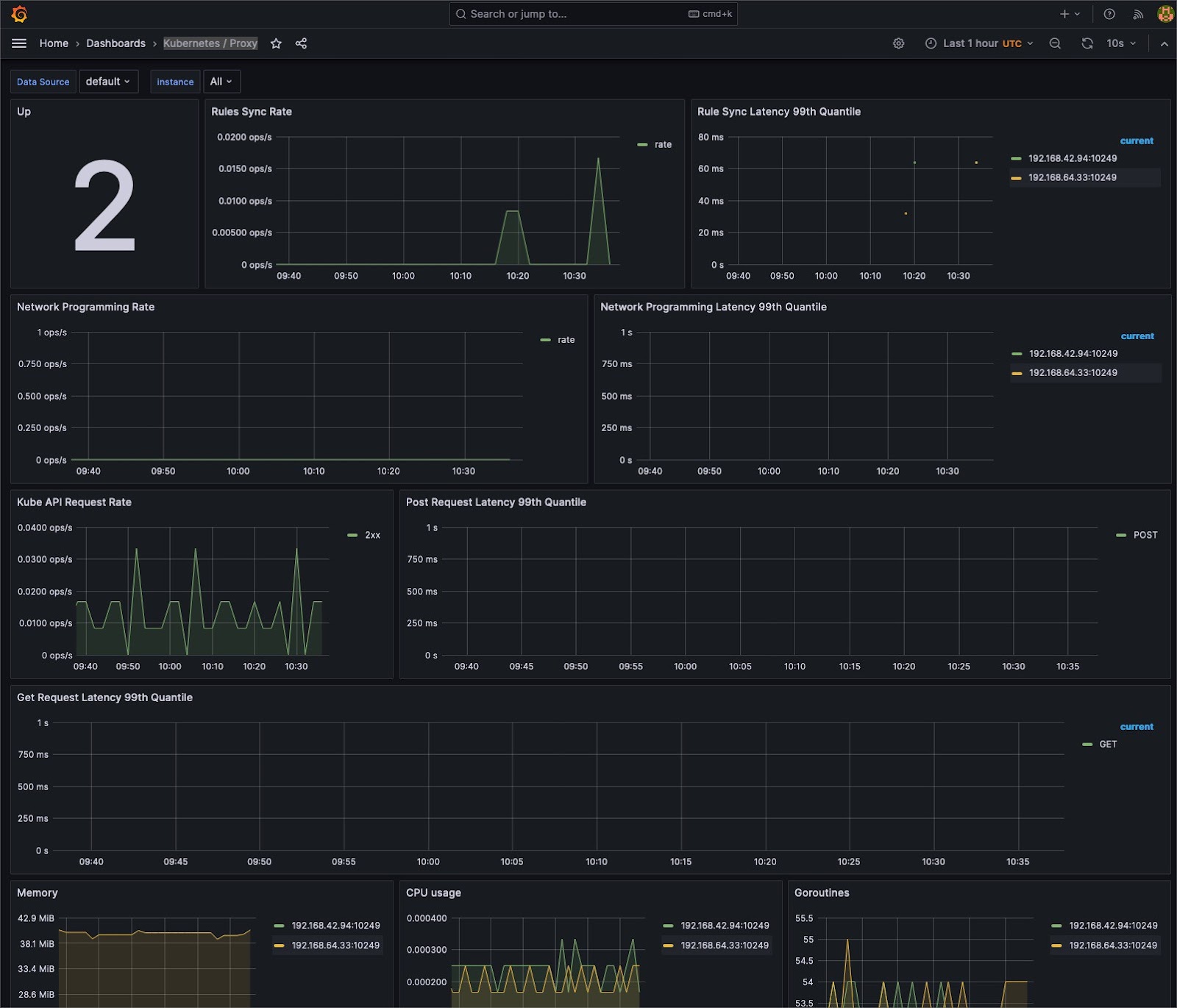
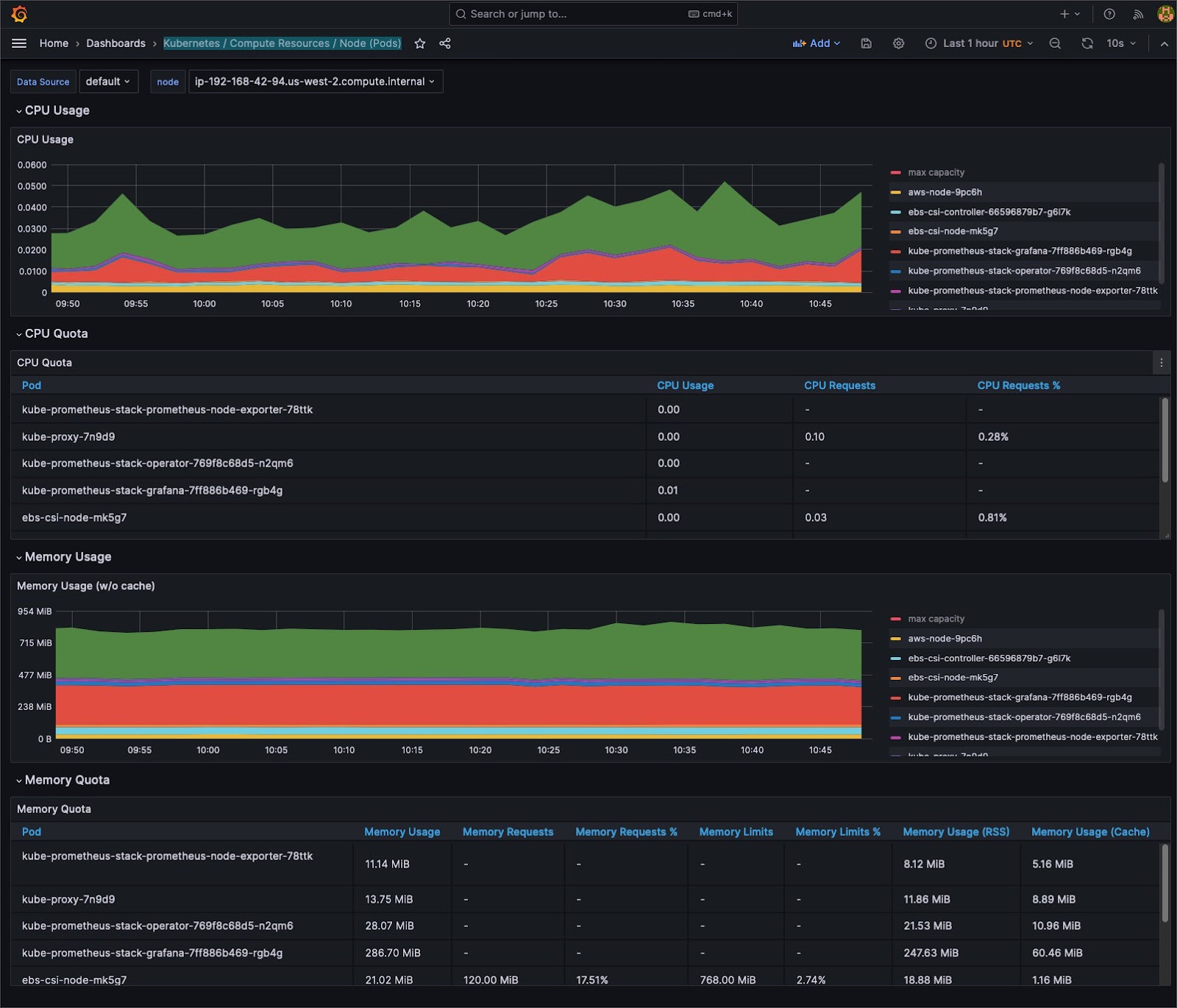
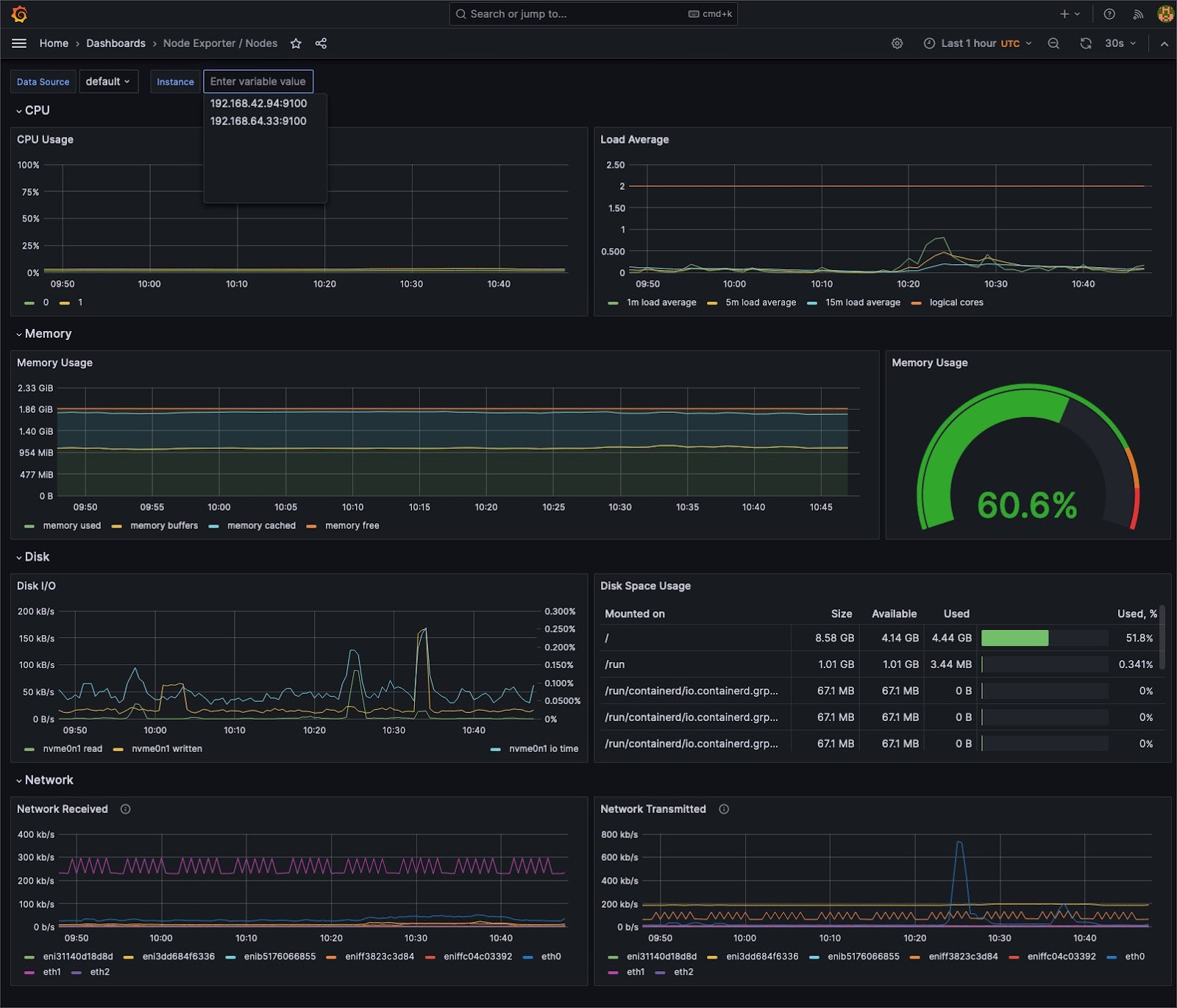
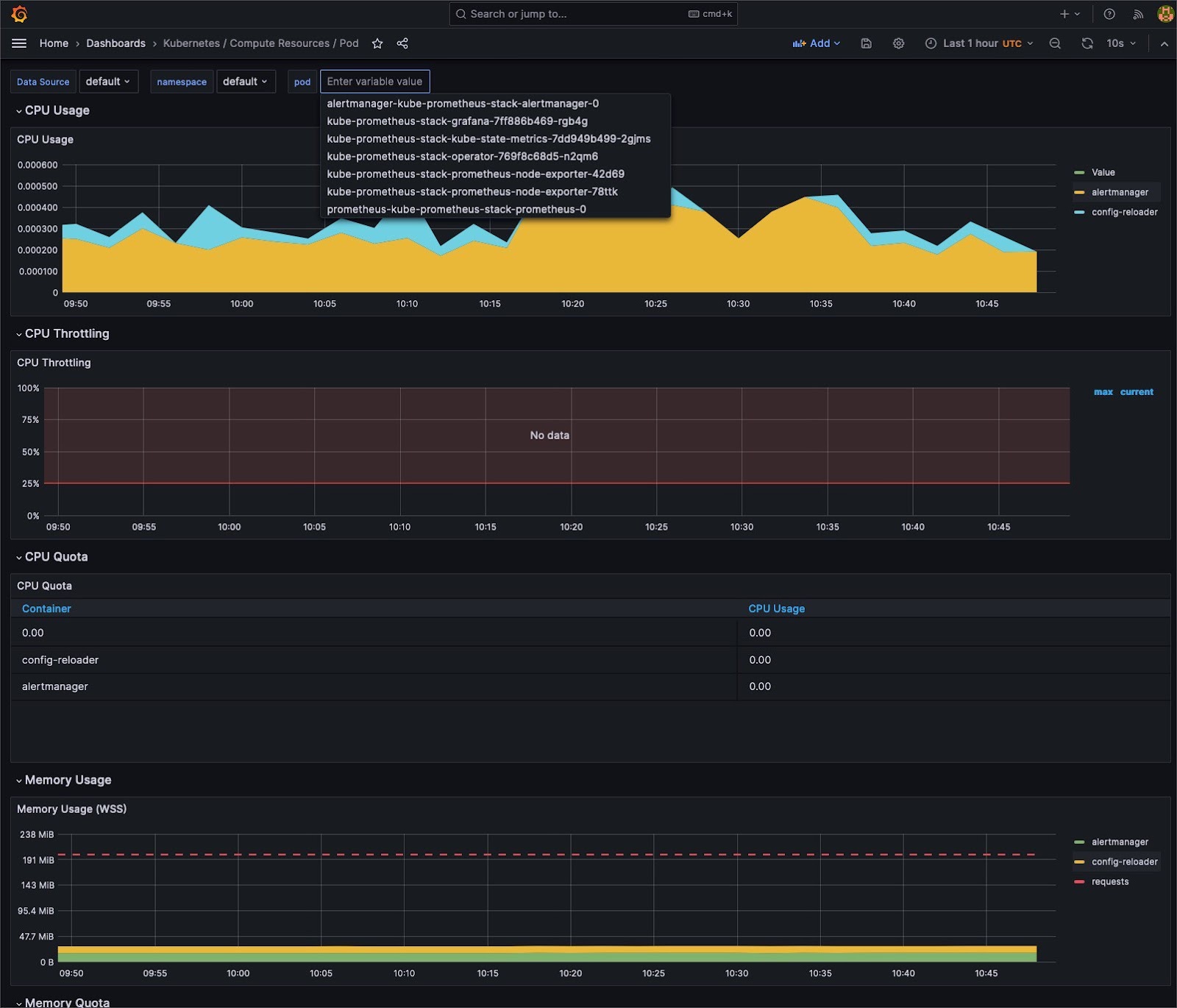
Understanding system behavior often requires different levels of detail. Aggregate metrics offer a holistic system overview, but granular data can pinpoint specific issues.
Cluster administrators can seamlessly switch between cumulative views and instantaneous snapshots by utilizing tools such as Prometheus, which supports counter and gauge metrics. This dual capability facilitates precise debugging and broad system health checks, ensuring that both micro and macro perspectives are attainable.
Use case: If your system’s response time suddenly increases, an aggregate metric might show the overall spike. However, granular data can pinpoint that a specific microservice, perhaps the user authentication service, is the root cause.
Set up meaningful alerts
Efficient alerting is all about catching anomalies without getting drowned in noise. Alertmanager stands out by integrating with Prometheus and providing functionalities like group-based alert routing, deduplication, and silencing. This sophistication ensures that alerts are generated and reach the appropriate teams in a format conducive to action, improving the signal-to-noise ratio.
Use case: Consider a scenario where a specific pod experiences frequent restarts. Instead of getting an alert for every restart, Alertmanager can consolidate these into a single alert with the number of restarts within a time frame.
Establish a baseline
For any monitoring system to detect anomalies, it must first understand the “norm.” Tools like Grafana provide the means to visualize data over time, allowing teams to identify typical cluster behavior patterns. This temporal understanding and a comprehensive time-series database provide the essential context for recognizing deviations, ensuring proactive responses rather than reactive firefighting.
Use case: Over the course of a month, you might observe that memory usage peaks every Friday. This pattern becomes your baseline, so if memory spikes unusually on a Wednesday, you know it’s an anomaly worth investigating.
Leverage auto-scaling based on metrics
The built-in auto-scaling capabilities of Kubernetes, such as the Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler, are potent mechanisms. When parameterized with precise metrics from Prometheus, they allow Kubernetes clusters to adapt in real time based on accurate metrics to ensure optimal resource utilization, balancing performance with cost.
Use case: Suppose an e-commerce application experiences a surge in traffic during a sale. With metrics-driven auto-scaling, Kubernetes can automatically spawn additional pods to handle the load, ensuring that the app remains responsive.
Monitor cluster dependencies
Kubernetes interacts with many external systems, each a potential point of bottleneck or failure. Tools like Prometheus can be expanded with exporters to pull metrics from various sources, like databases, caches, or other services. By casting this wide monitoring net, you ensure that no internal or external component escapes scrutiny.
Use case: If an application relies on a Redis cache, monitoring the cache’s hit rate and response times can provide insights. A sudden drop in the hit rate might suggest an issue with the application logic.
Regularly review and update the monitoring setup
A static monitoring configuration can become a liability over time. As applications and infrastructure evolve, so should the monitoring setup. The Prometheus Operator simplifies management and updates, especially with custom resources like service monitors.
Regular reviews ensure that monitoring remains aligned with the dynamic nature of Kubernetes deployments.
Use case: A new service added to your application should be accompanied by relevant monitoring checks. If you deployed a new payment gateway, you would want metrics and alerts for its response times and failures.
As the ecosystem evolves, so should the monitoring setup. Regular revisions ensure that the monitoring remains in tune with the current state of Kubernetes deployments.
Set up proactive controls with probes in Kubernetes
Kubernetes offers proactive controls that enable administrators to maintain the health and performance of applications and nodes. Liveness, readiness, and startup probes are vital tools in this regard:
- Liveness probes: These probes ensure that applications within containers are running correctly. If an application fails the liveness probe, Kubernetes restarts the container, providing self-healing capabilities to resolve issues such as deadlocks or unresponsive processes.
- Readiness probes: These probes determine if a pod is ready to accept traffic. This ensures that services don’t route traffic to pods that aren’t ready, which is crucial during startup or after a deployment.
- Startup probes: As suggested by the name, startup probes are used to manage the startup phase of a container. For applications with a slow startup time, a startup probe ensures that Kubernetes doesn’t kill the application before it’s fully started. It provides a way to delay the execution of liveness and readiness probes, giving long-starting applications enough time to initialize.
Integrate cost monitoring with Kubecost
Cluster efficiency is a balancing act between performance and cost. Kubecost was explicitly built for Kubernetes and bridges the gap between operational metrics and financial insights. It delves deeply into Kubernetes metrics, extrapolating granular cost data. This approach ensures that you track performance and understand the financial implications of your cluster’s behavior.
By segmenting costs based on parameters such as namespace, workload, or labels, Kubecost makes opaque cost structures transparent. Its integration with Grafana enhances visualization, enabling teams to spot trends, predict future costs, and make informed budgeting decisions. In addition, its alerts and efficiency recommendations provide actionable insights, assisting teams in optimizing both performance and costs.
With Kubecost, the financial dimension of Kubernetes operations becomes a tangible, manageable entity, promoting proactive cost management.