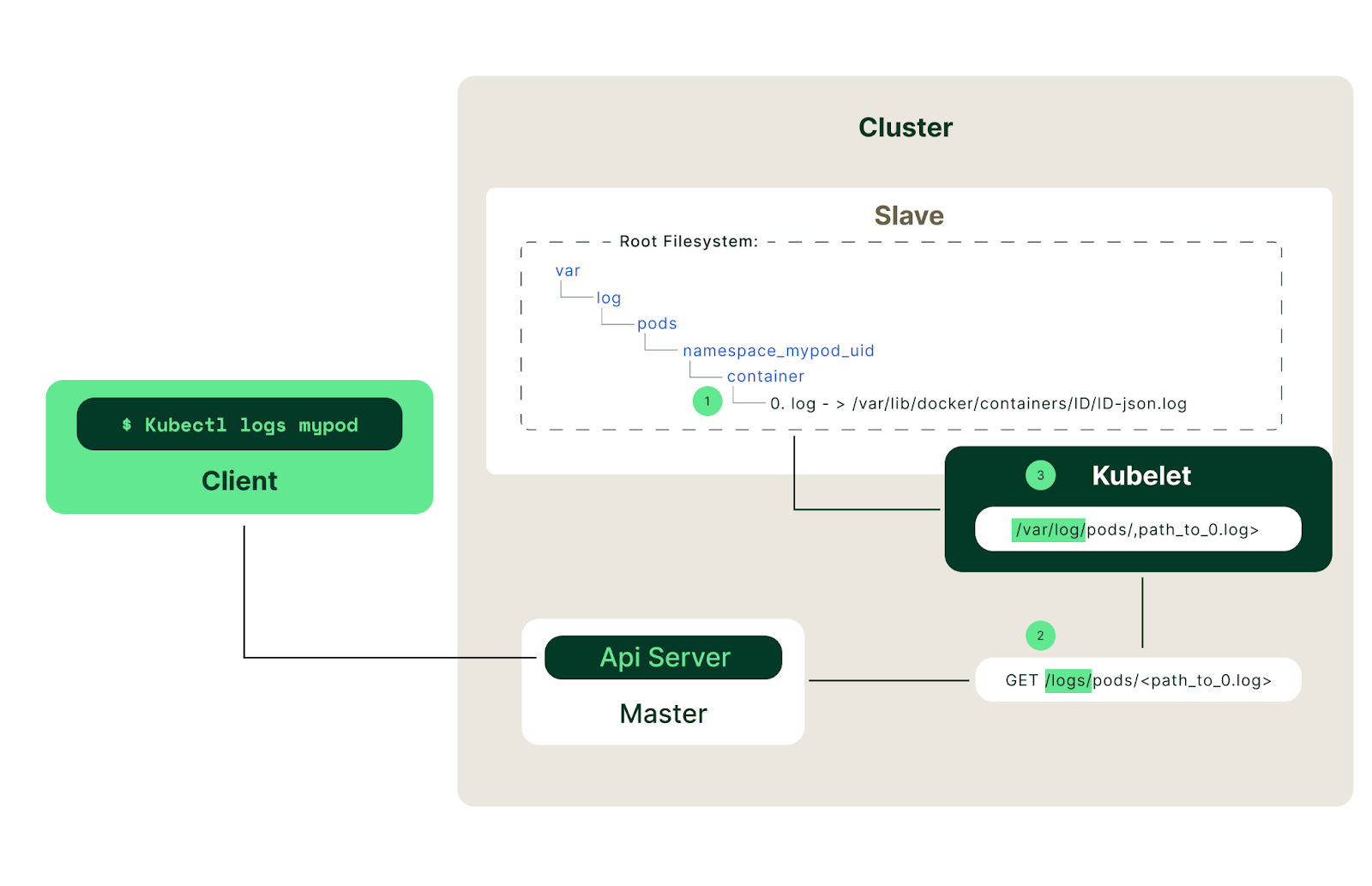
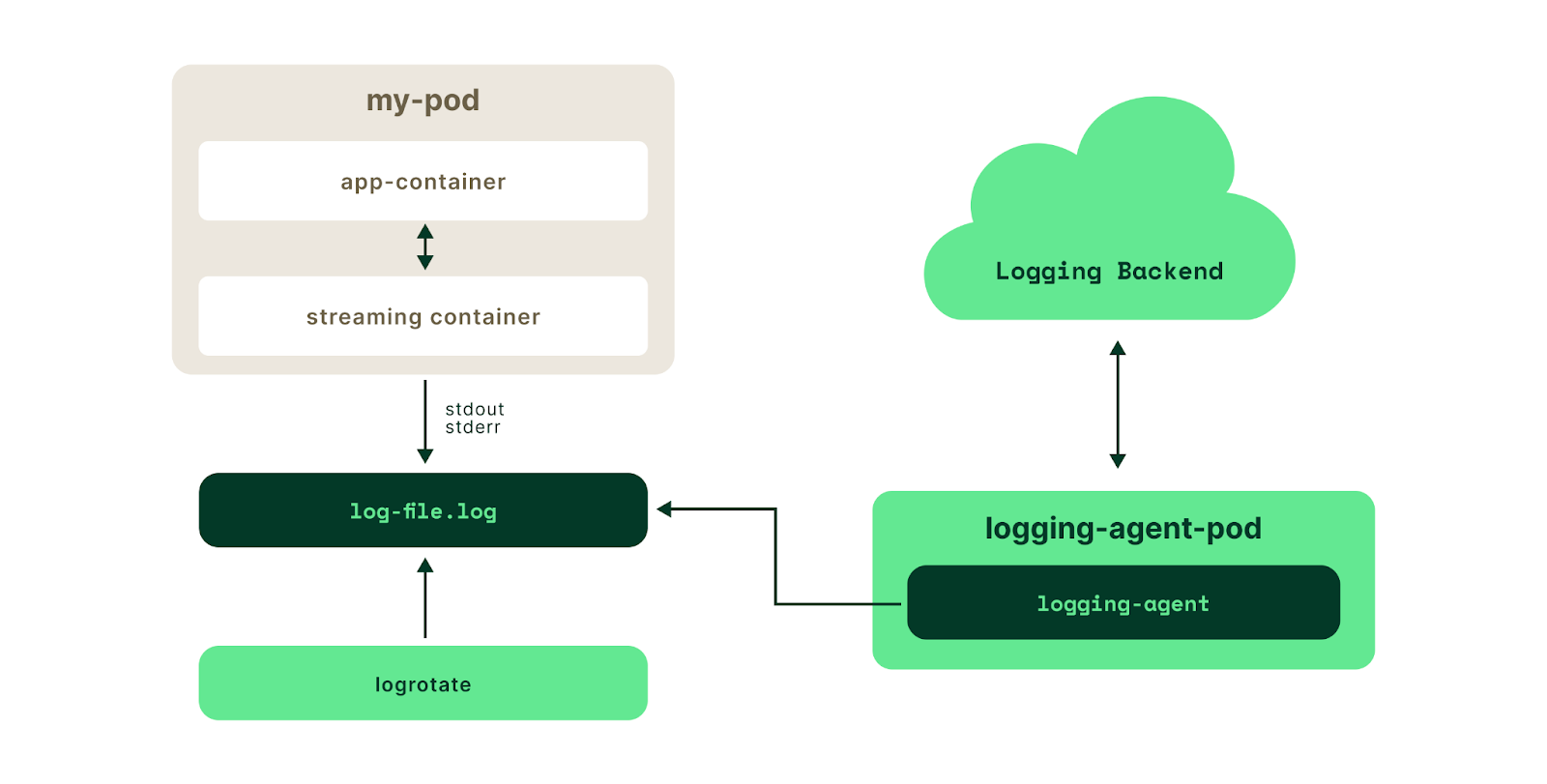
Example of centralized Kubernetes log storage
The starting point of shipping Kubernetes logs to a centralized log storage system is configuring a log collector and a logging driver. In the case of integration with the ELK stack, you configure the logging driver to send logs via Filebeat to Logstash, a data processing pipeline that collects, filters, and transforms logs before sending them to Elasticsearch, a distributed search and analytics engine. The steps are:
-
Configure a log collector, such as Filebeat, using the open-source helm chart. By default, Filebeat ships with ElasticSearch destination, so all you need to do at this stage is provide your ElasticSearch’s cluster details:
output.elasticsearch:
host: "${NODE_NAME}"
hosts: '["https://${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}"]'
username: "${ELASTICSEARCH_USERNAME}"
password: "${ELASTICSEARCH_PASSWORD}"
protocol: https
ssl.certificate_authorities: ["/usr/share/filebeat/certs/ca.crt"]
-
Alternatively, you can opt-in for changing Filebeat’s output configuration to send logs to Logstash instead. You can also deploy Logstash using the official open source
Helm Chart. You can filter or apply basic transformations on specific logs before sending them to ElasticSearch. Define the IP addresses to match where Logstash has been deployed to. You may also need to specify the port number if you have a Logstash port other than the default 5044.
output.logstash:
hosts: [”1.2.3.4.”]
-
Configure Logstash to receive the logs from FIlebeat:
input {
beats {
port => 5044
}
}
-
Finally, configure Logstash to push logs to Elasticsearch.
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "var-log-%{+YYYY.MM.dd}"
}
}
Once you receive logs in Elasticsearch, you can store them in indices based on their content and metadata. You can search and analyze these indices using the Elasticsearch API or Kibana, a web-based user interface for Elasticsearch. Kibana provides various visualization tools, such as charts, graphs, and dashboards, that enable users to explore and understand logs in real time.