You should backup your Kubernetes workloads, services, networking, config, storage, and cluster resources. Each of these components plays a crucial role in your Kubernetes environment.
Workloads
Workloads like Deployments, StatefulSets, DaemonSets, and ReplicaSets manage your applications and maintain the desired state and scale. They encapsulate the configurations required for the successful deployment of your pods. By backing them, you can quickly redeploy your applications and reduce the risk of service disruptions. Moreover, the backup of these resources is critical if you plan to roll out your application to a new Kubernetes cluster.
Jobs and Cronjobs
In Kubernetes, Jobs and CronJobs represent one-off and scheduled tasks, respectively. Backing up their configurations ensures:
- Continuity of the functions across cluster disruptions.
- Swift recreation of critical batch jobs if necessary.
This is particularly important in data processing or machine learning scenarios, where these jobs might form crucial parts of larger pipelines.
Services & Networking
Services in Kubernetes provide a consistent way of accessing your applications. They abstract away the complexity of managing pod lifecycles and provide stable network access. Backing up your service configurations ensures that your networking setup remains consistent and minimizes disaster impact on your end-users.
Ingress
Ingress rules define how incoming traffic should be routed to services within your cluster. These rules, especially in complex microservices setups, can be intricate. Having a backup of your Ingress configurations saves you from the arduous task of manually recreating them in case of a loss. You can ensure the external access patterns to your services remain consistent.
NetworkPolicies
NetworkPolicies govern the permissible communication paths between services within your cluster. Backing them up is crucial to preserve your network's security posture. It ensures that your services continue interacting and maintain the same access controls and traffic flow rules even after a disruption.
Config
ConfigMaps and Secrets hold non-confidential and confidential configuration data that applications require to run correctly. By backing them up, you ensure the configurations and sensitive information (like credentials) your applications depend on are always available. You can use built-in backup methods if you use external sources like AWS SSM Parameters, AWS Secrets, or Hashicorp Vault to manage the configuration and secrets.
Storage
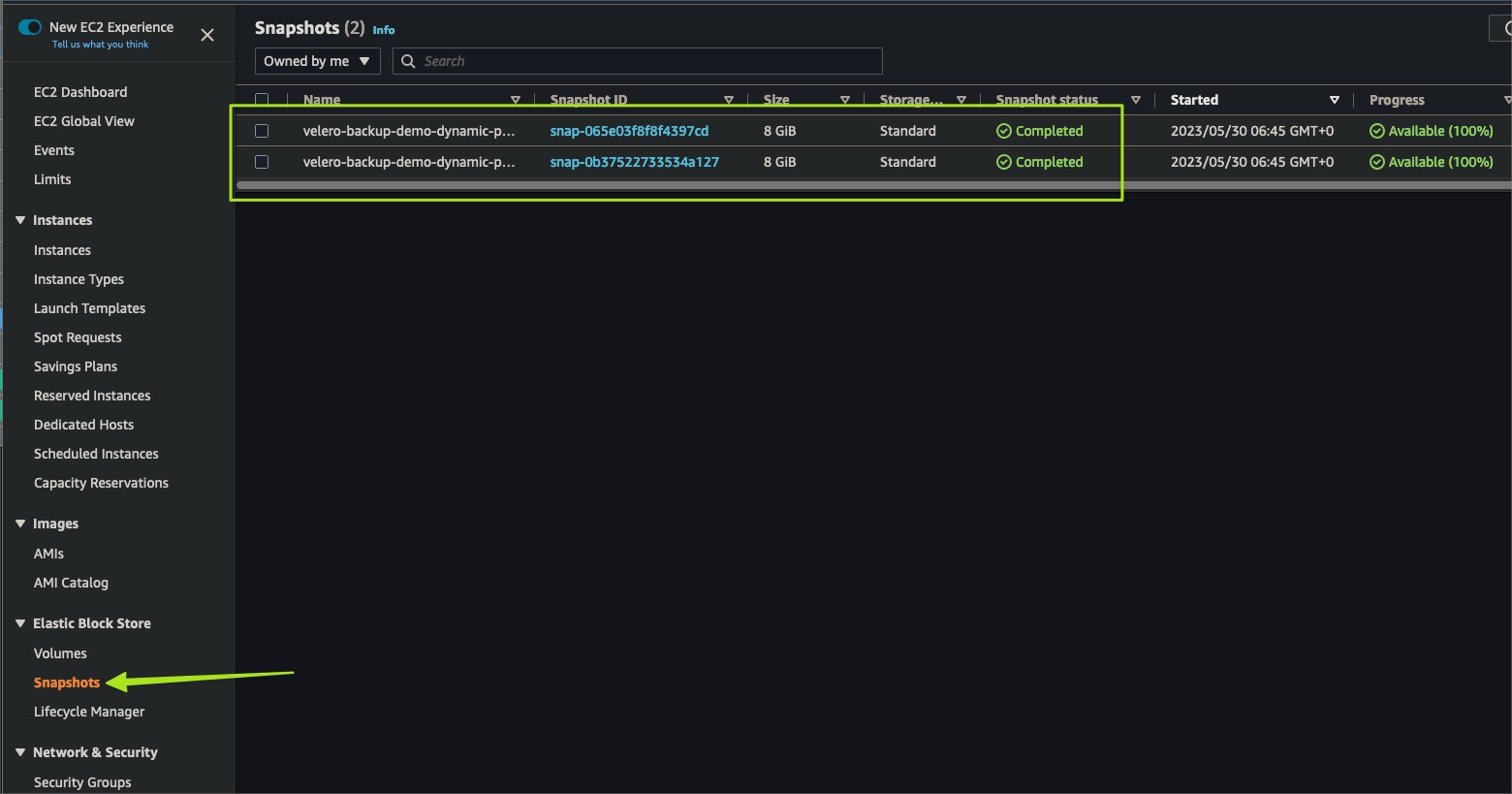
PersistentVolumeClaims represent your pod’s storage requests. A backup of your PVs ensures that Kubernetes appropriately reprovisions any storage attached to your workloads if a disaster occurs. It preserves the storage configurations that your applications rely on, ensuring data consistency.
Cluster resources
Kubernetes Namespaces segregates cluster resources among multiple users, applications, or environments. Backing up Namespace information helps you recreate your cluster's exact organizational and access control boundaries after a disaster.
RBAC settings
RBAC settings like Roles and RoleBindings in Kubernetes dictate who can do what within a namespace or a cluster. These rules are vital for maintaining access controls within your cluster. Backing them ensures you can quickly restore your cluster's correct permissions and access controls.
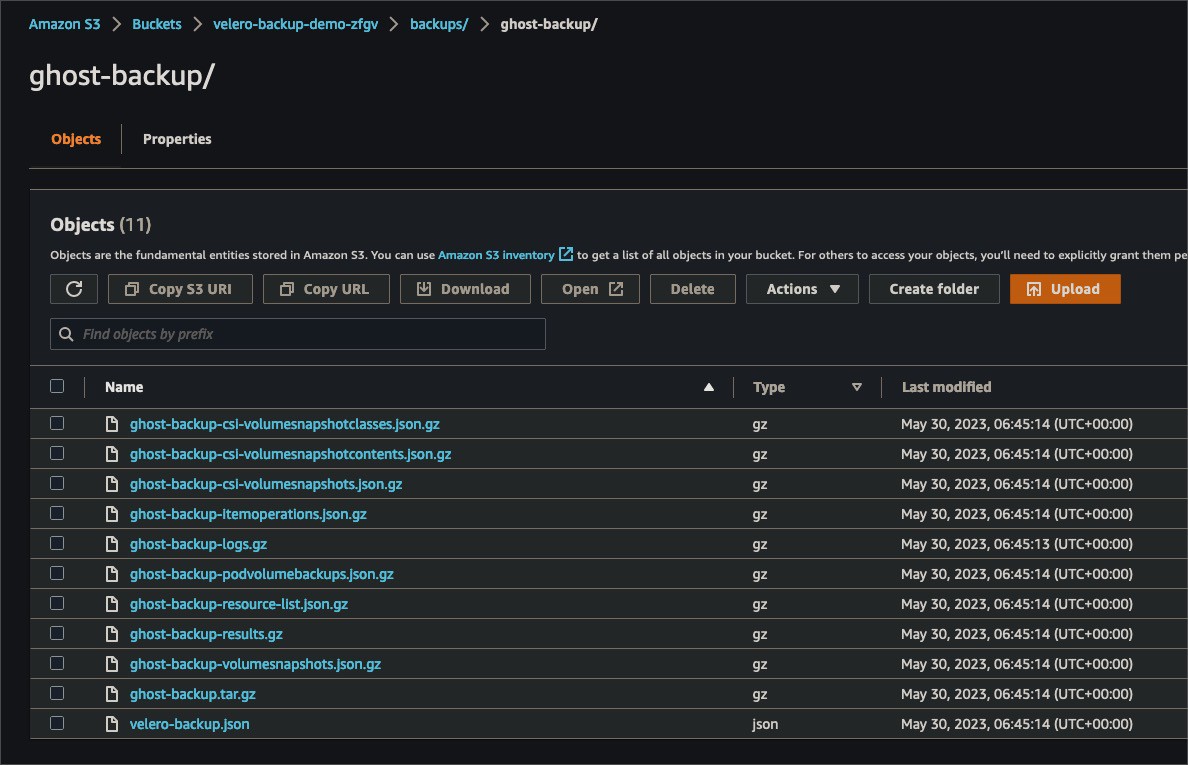
Velero is an open-source tool that can back up, recover, and migrate Kubernetes cluster resources and persistent volumes. It utilizes Custom Resource Definitions (CRDs) to execute various commands in the cluster.
CRDs are an extension of the Kubernetes API that allows you to create new custom resources and define the desired application functionality within the cluster. In the context of Velero, these CRDs define and control the backup and restoration processes.
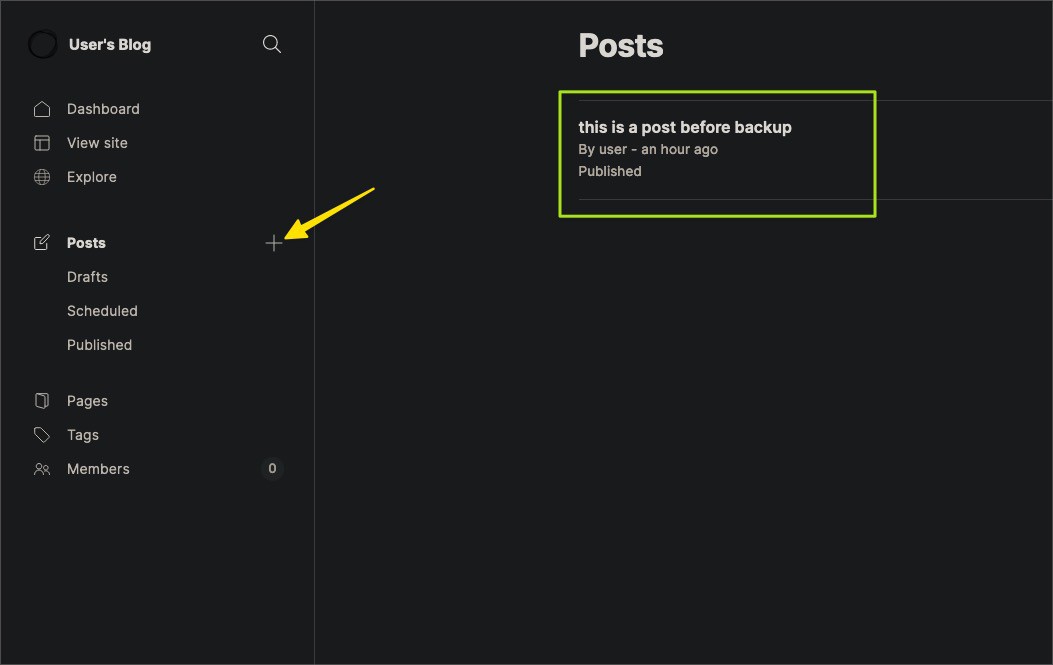
For instance, when you want to create a backup of your cluster, a backup CRD is submitted to the cluster. This CRD provides instructions to the Kubernetes API, defining what needs to be backed up.
Creating these manually can be challenging, so the Velero team has developed a user-friendly CLI for performing backups and restores.
Key features of Velero include:
- Backup and restore all cluster resources (with their associated metadata), and restore them.
- Migrate cluster resources to other clusters, providing a way to recover from infrastructure loss.
- Regularly back up your Kubernetes objects and PVs and replicate them to a secondary cluster for disaster recovery.
Alternatives to Velero
Several other tools provide Kubernetes backup functionality.
Kasten K10 is a purpose-built data management platform for Kubernetes, providing enterprise operations teams with an easy-to-use, scalable, and secure system for backup/restore disaster recovery and mobility of Kubernetes applications.
TrilioVault for Kubernetes is a native data protection platform offering backup, recovery, cloning, and migration capabilities.
Portworx PX-Backup is a multi-cluster Kubernetes backup solution for applications and their data, supporting backup and restoration of applications and their data across different cloud providers.
These tools have unique features and may better suit specific use cases or environments. Evaluate a few options to find the best fit for your needs.